7 RAG Deals Reshaping How Enterprise AI Accesses Data

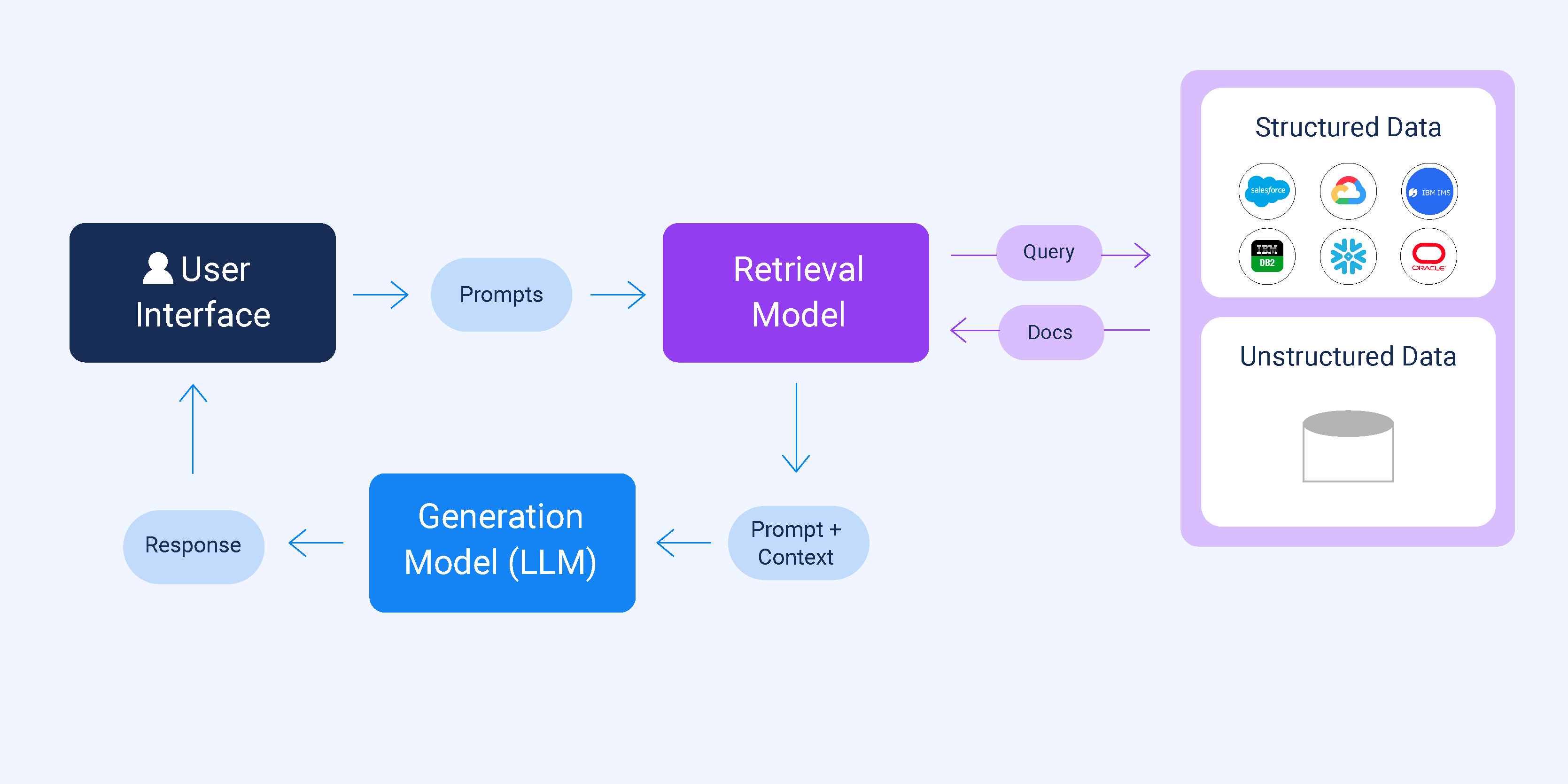
A quiet but consequential shift is underway in how enterprise RAG systems get built: legal data access has become the binding constraint, and it is now outpacing the purely technical challenges of retrieval. A new analysis from RAG About It maps seven active licensing deals reshaping how enterprise AI pipelines access data, with the News/Media Alliance and Bria partnership serving as the most striking example — it now channels licensed content from more than 2,200 publishers into enterprise models through a revenue-sharing structure. The implication is that the quality ceiling for any RAG system is increasingly determined not by embedding model choice or chunking strategy, but by what data can be legally and reliably retrieved in the first place.
The economics are not trivial. Attribution-aware RAG architectures add roughly 15 to 20 percent in development complexity compared to unconstrained retrieval setups, but they reduce legal review cycles by an estimated 60 percent — a trade-off that becomes very attractive at enterprise scale when legal review is a recurring bottleneck. For teams building pipelines on LangChain, LlamaIndex, or LangGraph, the practical upshot is that data provenance and licensing layers should be considered architectural concerns from the start, not compliance add-ons applied late in the development cycle.
The argument the piece closes with is worth internalizing: your RAG system's intelligence is only as good as the data you can legally, reliably, and economically retrieve. As licensed data partnerships multiply and courts continue issuing rulings on training and retrieval, the teams that design for provenance early will have a significant structural advantage.