Claude Opus 4.7 Tops the Benchmarks, but the LLM Market Is Still Buying a Portfolio

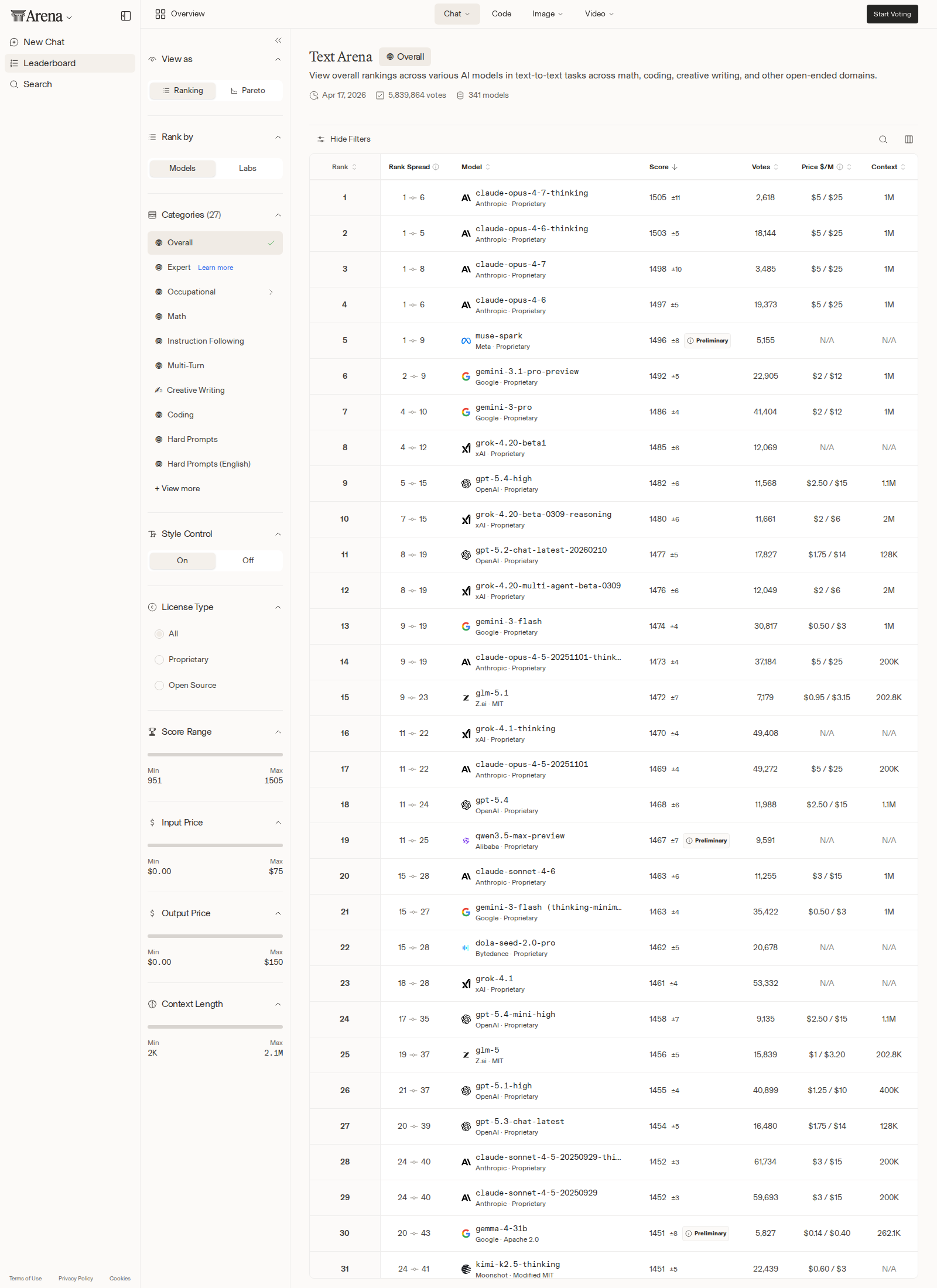
Benchmarks are supposed to settle arguments. In the LLM market, they mostly start new ones. This week Anthropic grabbed the cleanest possible headline, with Claude Opus 4.7 landing at the top of both Arena Text and Arena Code, but the more useful story for people actually shipping software is that leaderboard dominance and production demand are still diverging in plain sight.
On Arena Text, Claude Opus 4.7 Thinking debuted at 1505 Elo, just ahead of Claude Opus 4.6 Thinking at 1503. The non-thinking Opus 4.7 also entered at #3 with 1498, while Opus 4.6 slipped to #4 at 1497. Arena Code was even less ambiguous: Claude Opus 4.7 took #1 at 1583 Elo, pushing Claude Opus 4.6 Thinking and Claude Opus 4.6 down to second and third. If you wanted a scoreboard screenshot for a launch deck, Anthropic got one.
Anthropic’s own announcement leaned into that exact narrative. The company said Opus 4.7 improves on Opus 4.6 in advanced software engineering, especially on hard, long-running tasks, and highlighted external tester results that would make any model team happy to paste into a slide: 70% on CursorBench versus 58% for Opus 4.6, 3x more production tasks resolved on Rakuten-SWE-Bench, and a jump on XBOW’s visual-acuity benchmark from 54.5% to 98.5%. Just as important for buyers, Anthropic says pricing is unchanged at $5 per million input tokens and $25 per million output tokens.
That combination matters. A big performance jump with flat pricing is one of the few things that can actually change routing decisions quickly, because it does not require procurement to relearn the budget. The usual friction in model adoption is not only technical risk. It is also spreadsheet risk. If the better model costs the same, a lot of internal arguments disappear.
The market still does not buy models the way benchmarks rank them
Now the part vendors like less: the usage leaderboard is telling a messier story. OpenRouter’s current rankings are led not by the new Arena winner, but by Claude Sonnet 4.6 with 1.37 trillion tokens, followed by Claude Opus 4.6 with 1.32 trillion and DeepSeek V3.2 with 1.28 trillion. The rest of the top ten is a coalition, not a monarchy: Gemini Flash variants, MiniMax, Xiaomi’s MiMo-V2-Pro, and Gemini 3.1 Pro Preview all have real share.
That split is the most important fact in this week’s rankings. Arena measures broad pairwise preference. OpenRouter usage measures what people actually choose to run through production traffic, cost constraints, and reliability needs. Those are related metrics, but they are not interchangeable. Plenty of engineering teams would happily admit that the benchmark leader is not the model they want handling most of their tokens on Tuesday afternoon.
There is a second signal here that looks more durable than a single launch spike: the fastest growers in the OpenRouter top 20 were GLM 5.1 (+222%), Qwen3.6 Plus (+156%), MiMo-V2-Pro (+140%), and Gemini 3.1 Pro Preview (+130%). That is not what a winner-take-all market looks like. It looks like buyers segmenting workloads by price, latency, policy constraints, and task shape, which is a more mature pattern than the “pick one frontier model and pray” era of 2024.
For practitioners, this is the useful correction to benchmark discourse: the question is no longer “Which lab won?” It is “Which model wins which job, under which constraints, at what cost?” If your team is still trying to answer that with a single provider default, you are leaving performance or margin on the table.
Anthropic’s real win is not just raw quality, it is timing
Opus 4.7 did not land into an empty field. It landed into a market where Google is still strong in fast multimodal work, where Chinese labs keep improving on cost-performance, and where OpenAI remains present but no longer automatically synonymous with the top slot in every public ranking. That makes the launch more impressive, not less. Anthropic did not win by being first. It won by shipping a model that moved both the text and code boards at the top.
But the company also shipped it with more explicit safeguards. Anthropic says Opus 4.7 is the first model released with new automated protections for prohibited or high-risk cybersecurity use, plus a Cyber Verification Program for legitimate security researchers. That may be prudent policy, but it also reinforces a practical reality: some teams will want Opus 4.7 for code quality and reasoning, while keeping other models in the stack for research-heavy or more loosely constrained workflows.
This is the part many benchmark roundups ignore. Capability is only one dimension of utility. Policy envelope is another. Availability through your existing vendors is another. Operational consistency is another. A model can be best-in-class and still not be your default if it collides with how your team actually works.
The weirdest counter-signal is also a healthy one
One of the better reminders not to overfit on grand narratives came from Simon Willison, who ran a very public and very unserious micro-benchmark: generate SVGs of a pelican on a bicycle and a flamingo on a unicycle. In his tests, a quantized local Qwen3.6 model running on a laptop produced better results than Opus 4.7 for those prompts. No, that does not mean Qwen has secretly surpassed Anthropic overall. Yes, it does mean narrow task fit still matters more than people want to admit.
That is worth taking seriously because real engineering work is full of “small weird tasks” that never appear on glossy launch charts. Structured extraction, code review precision, long-context document synthesis, latency-sensitive support flows, UI generation, batch summarization, offline or edge deployment, policy-sensitive automation, and price-capped agent loops all reward different model properties. The market is fragmenting because the workload landscape is fragmenting.
My read is that Anthropic has taken the premium capability crown this week, but it has not invalidated the rest of the field. If anything, Opus 4.7 raises the bar for what teams should expect from a top-tier coding model while making the case for more aggressive model routing everywhere else.
What engineers should do now
First, retest your coding and agent workflows instead of assuming your previous champion is still the best. If you use Cursor, Devin, CodeRabbit, or any internal harness for long-running engineering tasks, Opus 4.7 now deserves a fresh bake-off. Second, separate prestige workloads from bulk workloads. Use the expensive, highest-capability model where failure is costly, and keep cheaper or faster models for classification, extraction, triage, and straightforward generation. Third, log policy-related failures separately from quality failures. Teams often blame model intelligence for problems that are really about tool use restrictions or safety interventions.
And finally, stop reading a single leaderboard as a universal truth. Arena tells you who is winning broad preference tests right now. OpenRouter tells you where traffic is going. Neither one tells you your exact answer. The winning teams in 2026 are increasingly the ones that can interpret both boards, then ignore both when their own evals disagree.
Anthropic has earned the week’s headline. Claude Opus 4.7 is the new model to beat on public quality rankings, especially for code. But the larger market signal is that one model can win the crown while the industry keeps buying a portfolio. That is a healthier place than AI discourse usually admits, and a more useful one for people who have to ship.
Sources: Arena Text leaderboard, Arena Code leaderboard, Anthropic announcement, OpenRouter rankings, Simon Willison