Hy3 Has the Traffic, Claude Has the Taste Test

The useful story in today’s model rankings is not that Tencent “beat” Anthropic. That would be a lazy reading of a usage chart, and lazy readings are how teams end up wiring production systems to leaderboard vibes. The better story is sharper: developers are increasingly treating LLMs less like monarchs and more like infrastructure components. One model gets the expensive judgment calls. Another gets the flood of cheap, high-context, good-enough work. The ranking tables are finally starting to show that split in public.
OpenRouter’s weekly usage leaderboard now has Tencent’s paid Hy3 preview at #1 with 1.69 trillion weekly tokens, up a reported 845,622% week over week. The free Hy3 preview listing, which had been #1, slipped to #3 while still carrying 1.47 trillion tokens. That is not a disappearance. It looks like the launch-window traffic is moving from “try the free thing” toward “route real workloads through the paid thing.”
That distinction matters. Free credits can manufacture curiosity. Paid token volume is a stronger signal that somebody found a workload where the model clears the bar often enough to justify keeping it in the path.
The rest of the OpenRouter top five makes the picture more interesting, not less. Claude Sonnet 4.6 sits at #2 with 1.51 trillion tokens, up 13%. Claude Opus 4.7 is #4 with 1.46 trillion tokens, up 59%. Kimi K2.6 fell three places to #5 despite still growing 20% week over week with 1.43 trillion tokens. In other words, this is not a market where only one model is winning. It is a market where multiple large models are growing, but the ordering is being reshaped by routing economics.
The leaderboard you use depends on the job you are hiring for
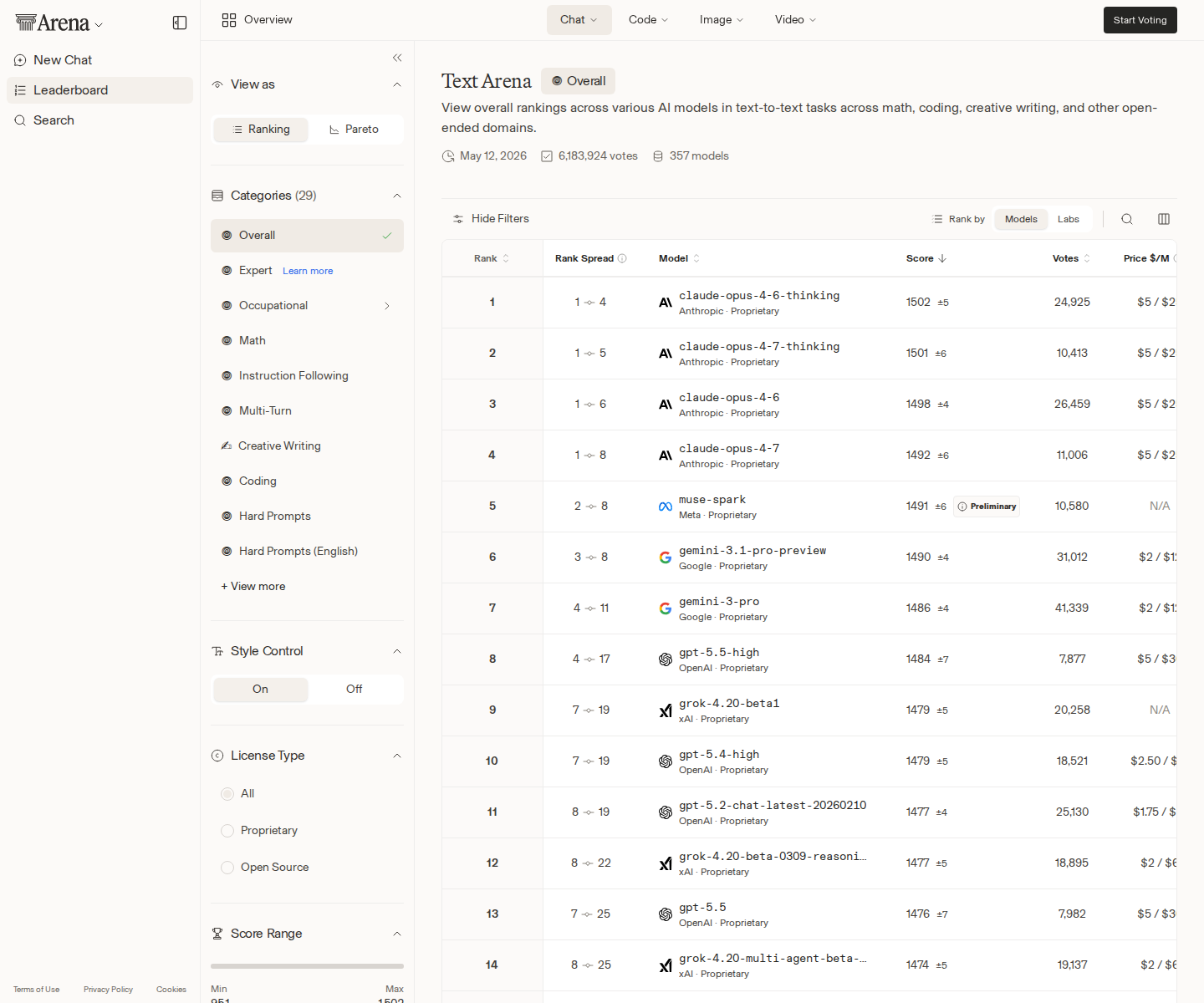
Now compare that with Arena. On the Text leaderboard, claude-opus-4-6-thinking retook #1 from claude-opus-4-7-thinking by a single Elo point: 1502 vs. 1501. With uncertainty bands of roughly ±5 and ±6, that is effectively a tie wearing a tiny crown. The top four Text slots are all Claude Opus variants: 4.6 thinking, 4.7 thinking, 4.6, and 4.7.
On Arena WebDev, Anthropic’s lead is less ambiguous. claude-opus-4-7-thinking remains #1 at 1566 Elo, followed by claude-opus-4-7 at 1559, claude-opus-4-6-thinking at 1547, and claude-opus-4-6 at 1544. The top four are all Opus. Sonnet 4.6 is still #6. Arena says the WebDev board reflects 299,865 votes across 77 models; Text reflects more than 6.18 million votes across 357 models.
That is the apparent contradiction: OpenRouter usage says Hy3 is suddenly carrying the most volume; Arena preference says Claude still owns the hardest coding and web development taste tests. The contradiction disappears once you stop pretending all “AI work” is one job.
Most production LLM systems are already pipelines, even if the architecture diagram still lies and shows a single box labeled “model.” A coding agent may use one model to plan, another to search, another to summarize files, another to generate boilerplate tests, and a more expensive model to review the final diff. A support automation system may use cheap long-context inference for retrieval and classification, then escalate ambiguous cases. A data product may run millions of low-stakes transformations where latency and cost dominate, while reserving premium reasoning for the few steps where a wrong answer burns user trust.
Hy3’s public positioning fits that infrastructure role. Tencent describes Hy3 preview as a Mixture-of-Experts model with 295 billion total parameters, 21 billion activated parameters, and a 256K token context window. It claims 54% lower Time To First Token, 47% lower end-to-end response time, greater than 99.99% success rate across CodeBuddy and WorkBuddy scenarios, complex agent workflows up to 495 steps, and a 40% inference-efficiency improvement. Vendor claims deserve a seatbelt. But those are exactly the claims that would explain massive token adoption if developers are trying to run background agents without lighting the cloud bill on fire.
Stop benchmarking models like they are sports teams
The operational mistake is to turn today’s OpenRouter table into “Hy3 is the best model.” It is not a quality leaderboard. It is a usage leaderboard. Usage is a composite metric made of price, free trials, latency, availability, default app settings, integrations, context length, current hype, refusal behavior, and actual model quality. That messiness is not a flaw in the data. It is the data telling you how production systems really behave.
For engineering teams, the action item is boring and important: build a routing matrix. Not a vibes doc. A real one. Evaluate candidate models by task class: planning, code editing, test repair, schema-constrained output, retrieval summarization, UI generation, long-context repo analysis, tool calling, and final review. Track latency, tool-call correctness, JSON adherence, refusal patterns, cost per completed task, and human acceptance rate. Cost per token is useful for procurement. Cost per successful unit of work is what engineering should care about.
Hy3 now deserves a serious eval for token-heavy, agentic workloads, especially if your product benefits from long context and lower latency. Start it in places where failure is cheap: summarization, scaffold generation, candidate patch drafting, log analysis, background research, and pre-review cleanup. Put it behind feature flags. Log its weird edges. Compare it against Sonnet, Opus, Kimi, DeepSeek, Gemini Flash, and your current default on completed-work cost rather than headline rank.
Claude, meanwhile, still looks like the safe default for high-stakes coding judgment. Arena WebDev’s top four being Opus variants is not subtle. If you are asking the model to reason across a messy codebase, make architectural calls, preserve UI intent, or review a diff that will ship to production, the preference data says Anthropic remains the benchmark to beat. Sonnet 4.6’s OpenRouter volume also says plenty of teams still prefer the cheaper Claude workhorse over the prestige model for day-to-day throughput.
One underrated lesson in the Text board: keep older models in your eval set. Opus 4.6 thinking edging Opus 4.7 thinking by one Elo point is statistically tiny, but it is a useful reminder that new releases do not dominate every workload. Model upgrades are not dependency bumps you merge on Friday because semver looked polite. They can change style, refusal behavior, tool-use habits, and error modes. Your regression tests should include taste, not just task completion.
The market is splitting into two leaderboards because production needs two kinds of excellence. One is frontier judgment: the model you trust when the task is ambiguous, expensive to get wrong, and hard to verify automatically. The other is economic competence: the model that can chew through enormous amounts of context quickly enough and cheaply enough that you can put it everywhere.
That is good news for builders. A single-model monoculture was always the least interesting future. The winning stack now looks more like a database query planner than a beauty contest: route by workload, observe the result, fall back when confidence drops, and keep switching costs low. Today Hy3 has the traffic story. Claude still has the coding-preference story. The team that wins is not the one that picks a champion. It is the one that builds the router and lets production telemetry overrule the fan club.
Sources: OpenRouter rankings, Tencent Hy3 preview announcement, Arena Text leaderboard, Arena WebDev leaderboard, Anthropic Claude Opus 4.7 announcement, Arena methodology