Hy3 Is Turning Free Tokens Into Real Traffic

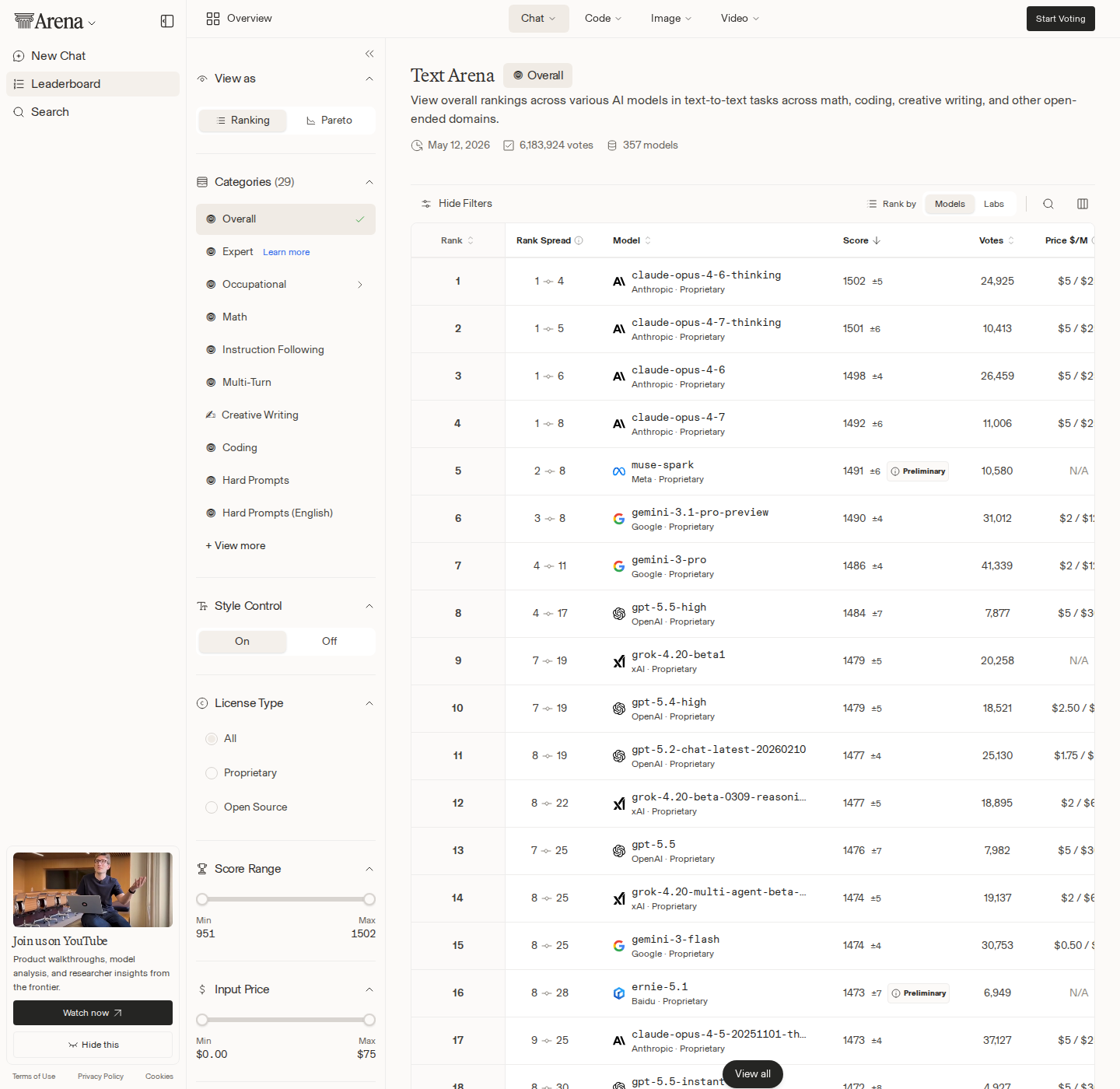
The LLM leaderboard story this week is not that a new model dethroned Claude. It did not. Arena AI’s Text and Code charts are basically frozen, with Anthropic still sitting on the top four Code slots and three of the top five Text slots. The more useful signal is happening somewhere messier: OpenRouter usage, where Tencent’s Hy3 preview now appears twice in the top five — once as the free route at #1, and now as the paid/default route at #5.
That distinction matters. Free model launches can manufacture impressive token graphs the same way free pizza can manufacture attendance at a meetup. Paid-route movement is harder to hand-wave away. It suggests that at least some developers are not just sampling Hy3 because the marginal cost is zero; they are continuing to send real workloads through it after the trial-shaped dopamine wears off.
OpenRouter’s weekly ranking now shows Hy3 preview (free) at 2.07 trillion tokens, up 40% week over week, and Hy3 preview’s standard route at 1.3 trillion tokens after jumping three ranks from #8 to #5. The rest of the top five is no slouch list: Kimi K2.6 at 1.53 trillion tokens, Claude Sonnet 4.6 at 1.49 trillion, and Claude Opus 4.7 at 1.33 trillion. Tencent is not nibbling at the edge of the routing market here. It is sitting next to the models teams already trust for serious agent and coding workflows.
Usage is not quality, but it is not noise either
The easy bad take is “Hy3 beats Claude.” Arena does not support that. On Arena AI Text, Claude Opus 4.7 Thinking remains #1 at 1503 Elo, followed by Claude Opus 4.6 Thinking at 1502 and Claude Opus 4.6 at 1498. Google’s Gemini 3.1 Pro Preview is the first non-Anthropic entry at #4 with 1492 Elo, followed by Claude Opus 4.7 at #5. On Arena Code, the picture is even less ambiguous: Claude Opus 4.7 Thinking, Claude Opus 4.7, Claude Opus 4.6 Thinking, and Claude Opus 4.6 own the top four positions.
That is the useful split. Arena is a preference and quality signal. OpenRouter is an adoption, availability, and cost signal. Engineers should not collapse those into one imaginary “best model” chart, because that is how teams end up using a benchmark winner for a cheap extraction job or a bargain model for a correctness-critical coding assistant. The leaderboard that matters depends on the failure mode you care about.
Hy3’s surge is plausible because the model is built for the kind of workloads that produce absurd token volume. Tencent describes Hy3 preview as a 295-billion-parameter Mixture-of-Experts model with 21 billion active parameters, 3.8 billion MTP layer parameters, 192 experts with top-8 activation, and a 256K token context window. In plain engineering terms: it is trying to offer long-context capacity without paying dense-model prices on every token. That is exactly the shape you want for document processing, codebase sweeps, retrieval-heavy agents, and “read all of this and produce structured output” jobs.
The vendor claims are also aimed squarely at production concerns, not just benchmark screenshots. Tencent says Hy3 delivered a 40% inference-efficiency improvement, 54% lower Time To First Token, 47% lower end-to-end response time, and greater than 99.99% success rate across CodeBuddy and WorkBuddy deployments. It also claims real-world agent workflows up to 495 steps across document processing, data analysis, knowledge retrieval, and MCP toolchain orchestration.
Those numbers are worth testing. They are not worth believing by default. Vendor latency and reliability claims often measure a stack you do not run, on traffic you do not have, with success definitions you would not ship. But they tell you what Tencent is optimizing for: not just chat quality, but agent throughput, long-context economics, and integration convenience.
The paid route is the tell
The paid Hy3 route moving from #8 to #5 is more interesting than the free route staying at #1. Free access can pull in students, benchmark tourists, bot traffic, weekend projects, and every engineer who wants to see if the new shiny thing survives their usual “summarize this horrifying PDF” test. Paid/default traffic is a slightly cleaner signal that Hy3 is good enough, cheap enough, or fast enough for workloads someone wants to keep running.
That does not mean the model is ready to replace Claude in coding agents. Arena Code says the opposite. Claude’s lead in the top four positions is a reminder that coding quality is not merely about generating plausible diffs. It is about following a long chain of constraints, preserving intent, recovering from partial failures, and not hallucinating your build system into a ditch. If the task is a senior-engineer-adjacent coding assistant where a wrong answer costs real review time, Claude remains the baseline to beat.
But plenty of production AI work is not “best possible answer.” It is “acceptable answer at terrifying volume.” Extraction, classification, draft generation, log analysis, long-document triage, test fixture generation, migration scaffolding, and internal knowledge-base querying all reward a different frontier: low latency, large context, tool-call support, stable routing, and price. Hy3 may be winning attention because it sits on that frontier.
The deployment story reinforces that this is not a casual local-model moment. The Hugging Face docs recommend serving Hy3 preview on eight GPUs using vLLM or SGLang, with explicit tool-call and reasoning parsers. Open-weight does not mean “your team will run this under someone’s desk.” For most builders, the practical decision is not self-hosting versus API purity. It is whether OpenRouter, Tencent TokenHub, or another managed route gives you reliable latency, clear data terms, sane pricing, and enough quality headroom for your workload.
What engineers should actually do
If you own an LLM stack, Hy3 belongs in the eval matrix this week, not in production by leaderboard osmosis. Build three tests: one for long-context extraction, one for multi-step agent/tool use, and one for codebase reasoning. Compare it against DeepSeek V4 Flash, Kimi K2.6, Gemini Flash, Claude Sonnet, and whichever OpenAI model you already use as the boring incumbent. Measure cost per successful task, not cost per token. Cheap tokens are expensive if they create retries, review burden, or silent data-quality failures.
Also split your evals by task criticality. For low-risk, high-volume pipelines, Hy3’s economics and context window may matter more than Arena rank. For user-facing coding, incident response, security review, or anything where a subtly wrong answer can cause damage, keep Claude or another proven high-reliability model as the reference. The correct architecture may be routing, not replacement: Hy3 for bulk context digestion, Claude for final reasoning and high-stakes edits.
There is a second-order industry point here too. OpenRouter’s chart is starting to look less like a quality leaderboard and more like a distribution leaderboard. That is not an insult. Distribution is how models become infrastructure. If Tencent can convert free access into paid traffic while staying competitive on latency and long-context workloads, it does not need to win every blind preference battle to matter. It just needs to become the default cheap capacity layer for enough builders.
The current state of the board is clean: Claude still looks like the quality king, especially for code; Tencent now looks like the adoption story to watch. Treat those as separate facts. The teams that benefit will be the ones that route accordingly instead of arguing about which single leaderboard is “real.”
Sources: OpenRouter Rankings, Arena AI Text leaderboard, Tencent Hy3 announcement, Hy3 preview on Hugging Face, Tencent-Hunyuan/Hy3-preview GitHub API.