LLM Rankings Are Stable at the Top and Chaotic Where It Counts

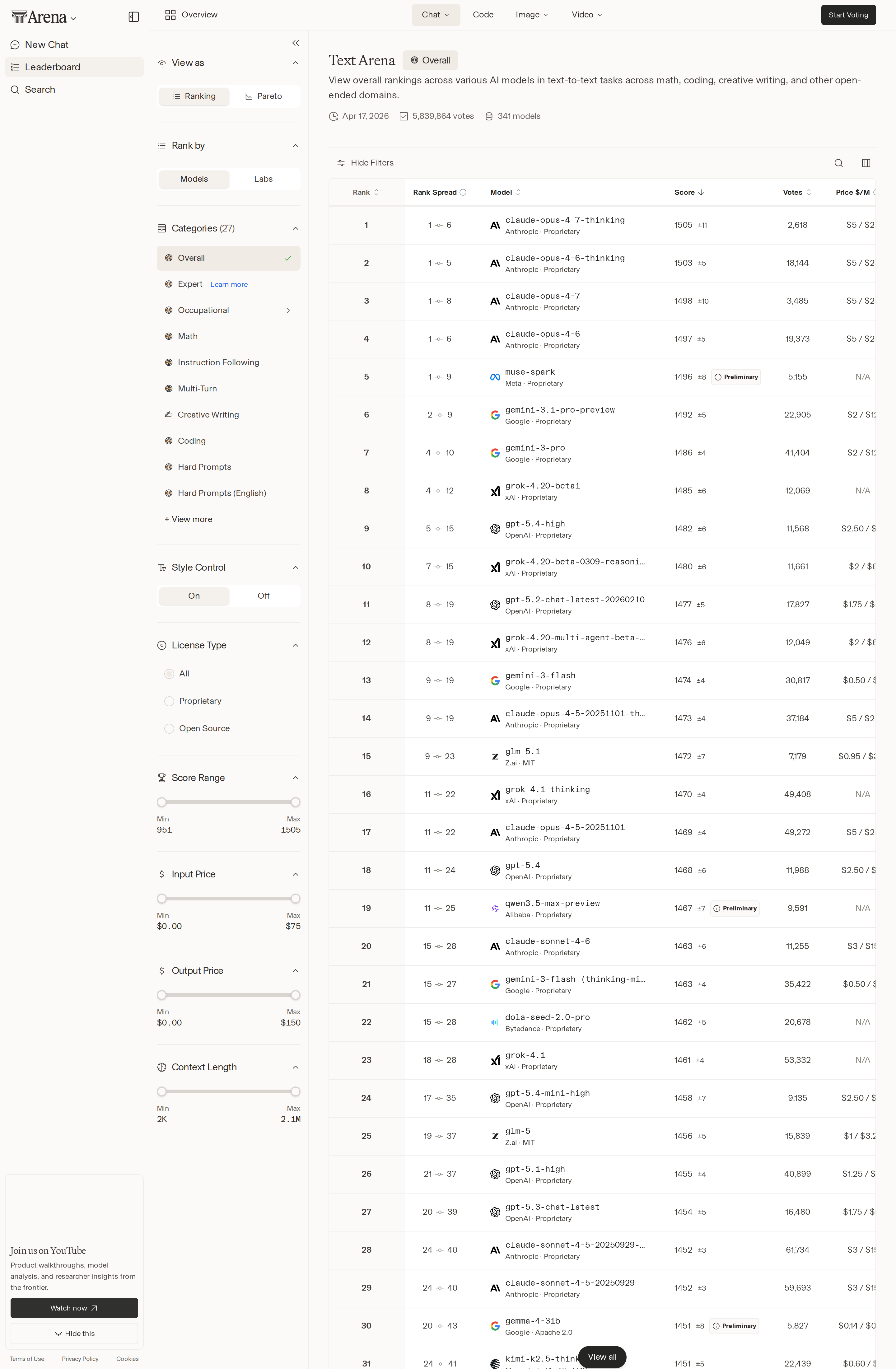
The easiest mistake to make with LLM rankings in 2026 is to stare at the top line and miss the market forming underneath it. Yes, Anthropic is still sitting on the Arena AI throne. Claude Opus 4.7 Thinking leads the text leaderboard at 1505 Elo, Claude Opus 4.6 Thinking is right behind at 1503, and Anthropic also holds four of the top five text spots and five of the top seven code spots. If you only need a winner, the answer is boring. If you care about where software teams will actually spend money and route workloads over the next six months, today’s more interesting signal is that the layer below the winner is getting crowded, unstable, and much more price sensitive.
Arena AI itself barely moved. The top 10 in both Text and Code looked effectively unchanged from the prior snapshot, which tells you the frontier model order is in one of those temporary plateaus that happen between major releases. On text, Meta’s Muse Spark stayed in fifth at 1496, Google’s Gemini 3.1 Pro Preview held sixth at 1492, and OpenAI’s GPT-5.4 High remained ninth at 1482. On code, Claude Opus 4.7 stayed first at 1583, with GLM-5.1 still a notable non-Anthropic outlier in fourth at 1538 and GPT-5.4 High (codex-harness) sitting eighth at 1457.
That stability matters, but not for the reason benchmark watchers usually think. It means the premium tier has become predictable enough that ranking position alone is no longer the full buying signal. Once the top handful of models are all clearly competent, teams stop asking “who is number one?” and start asking a more operational question: which model gets me acceptable quality at the best combination of cost, latency, context length, and reliability for this specific workflow?
The real action moved to the router layer
That is why OpenRouter’s ranking changes are more revealing than Arena’s stasis. Claude Sonnet 4.6 still holds the top usage slot at 1.37 trillion tokens, but the rest of the top 20 shifted in ways that look less like fandom and more like procurement. DeepSeek V3.2 climbed to number two with 1.28 trillion tokens, pushing Claude Opus 4.6 to third. Xiaomi’s MiMo-V2-Pro rose from sixth to fifth and crossed roughly 1.12 trillion tokens, overtaking MiniMax M2.5. GPT-5.4 jumped from fourteenth to eleventh. Google’s Gemini 3.1 Pro Preview suffered the sharpest drop in the top 20, falling from eighth to thirteenth. And Step 3.5 Flash entered the chart at number twenty with 302 billion tokens and 258 percent week-over-week growth.
This is what a market looks like when switching costs fall. API aggregators have turned model choice into a routing problem. The practical consequence is that reputation still gets you a trial, but price-performance gets you traffic. That is especially visible in MiMo-V2-Pro’s rise. Xiaomi says the model has more than 1 trillion total parameters, 42 billion active parameters, a 1 million token context window, and pricing that starts at $1 per million input tokens and $3 per million output tokens for contexts up to 256K. Those are the kinds of numbers that make infra teams open a spreadsheet, not just a demo.
Xiaomi also claims MiMo-V2-Pro scored 81.0 on PinchBench and 61.5 on ClawEval, placing it third globally on both of the company’s published charts. The more interesting detail is not whether every internal benchmark comparison survives independent scrutiny. It is that MiMo appears to be winning usage faster than it is winning mindshare. In the research brief, Hacker News discussion around MiMo was modest, with posts in the low single digits for points and comments, while Step 3.5 Flash drew a launch thread that reached 231 points and 91 comments. Developers are apparently discovering MiMo through routing layers and benchmark tables rather than social buzz. That usually means a model is solving a real budget or workload problem.
Step 3.5 Flash is the kind of entrant engineers actually test
Step 3.5 Flash, meanwhile, looks like the opposite kind of story. It entered lower on the usage chart, but with much louder practitioner attention. StepFun describes it as a 196 billion parameter sparse MoE model that activates only 11 billion parameters per token, supports a 256K context window, and typically generates at 100 to 300 tokens per second. The company also claims 74.4 percent on SWE-bench Verified and 51.0 percent on Terminal-Bench 2.0. Those are not abstract “general intelligence” numbers. They are the sort of benchmarks that prompt developers to drop a model into an agent harness and see whether it can survive a real task loop.
That combination, benchmark credibility plus unusually strong discussion, is why Step 3.5 Flash matters more than its number twenty placement suggests. New models often get one of two things: curiosity or adoption. Getting both in the same week is rarer. It suggests there is still room in this market for models that are not prestige defaults but are efficient enough to earn a place in production routing trees.
There is also a warning here for vendors that live in the expensive middle. Gemini 3.1 Pro Preview dropping five spots on OpenRouter, from eighth to thirteenth, does not mean Google has fallen out of the race. It still posted 496 billion tokens, which most companies would happily take. But it does suggest the middle of the leaderboard is now vulnerable to faster or cheaper alternatives. Once teams have a premium model for high-stakes work, they become ruthless about the rest of the stack.
What builders should actually do with this
If you are still hard-coding one preferred model across chat, coding, retrieval, and agent workflows, you are paying a tax for brand comfort. The obvious play now is a portfolio. Keep a premium default for tasks where failure is expensive. Keep a fast, cheaper model for bulk inference and internal tools. Keep at least one lower-cost or open-weight contender in active evaluation, not as a theoretical backup but as a model you benchmark weekly inside your own harness.
More concretely, three operating habits now matter. First, benchmark on your own tasks, not just public leaderboards. Arena and OpenRouter are useful directional signals, but your repos, prompts, tool schemas, and latency budgets are what matter. Second, measure routing economics, not just raw quality. A model that is slightly worse on paper but half the price and more stable in long-running agent flows will often ship more value. Third, stop treating community buzz as the same thing as usage reality. Step 3.5 Flash shows what developer excitement looks like. MiMo-V2-Pro shows what silent adoption looks like. You want visibility into both.
My working take is simple: Claude is still the safest answer if you want the least explanation in a room full of engineers. But the rankings that matter for the next quarter are not about who wins the headline. They are about whether teams can build a routing stack that exploits the growing gap between frontier prestige and practical sufficiency. That gap is widening. For buyers, that is good news. For vendors charging premium prices without obvious premium differentiation, it is a problem that no leaderboard screenshot can hide for long.
Sources: OpenRouter Rankings, Arena AI leaderboard, Xiaomi MiMo-V2-Pro, StepFun Step 3.5 Flash