LLM rankings: the leaderboard is quiet, the routers are not

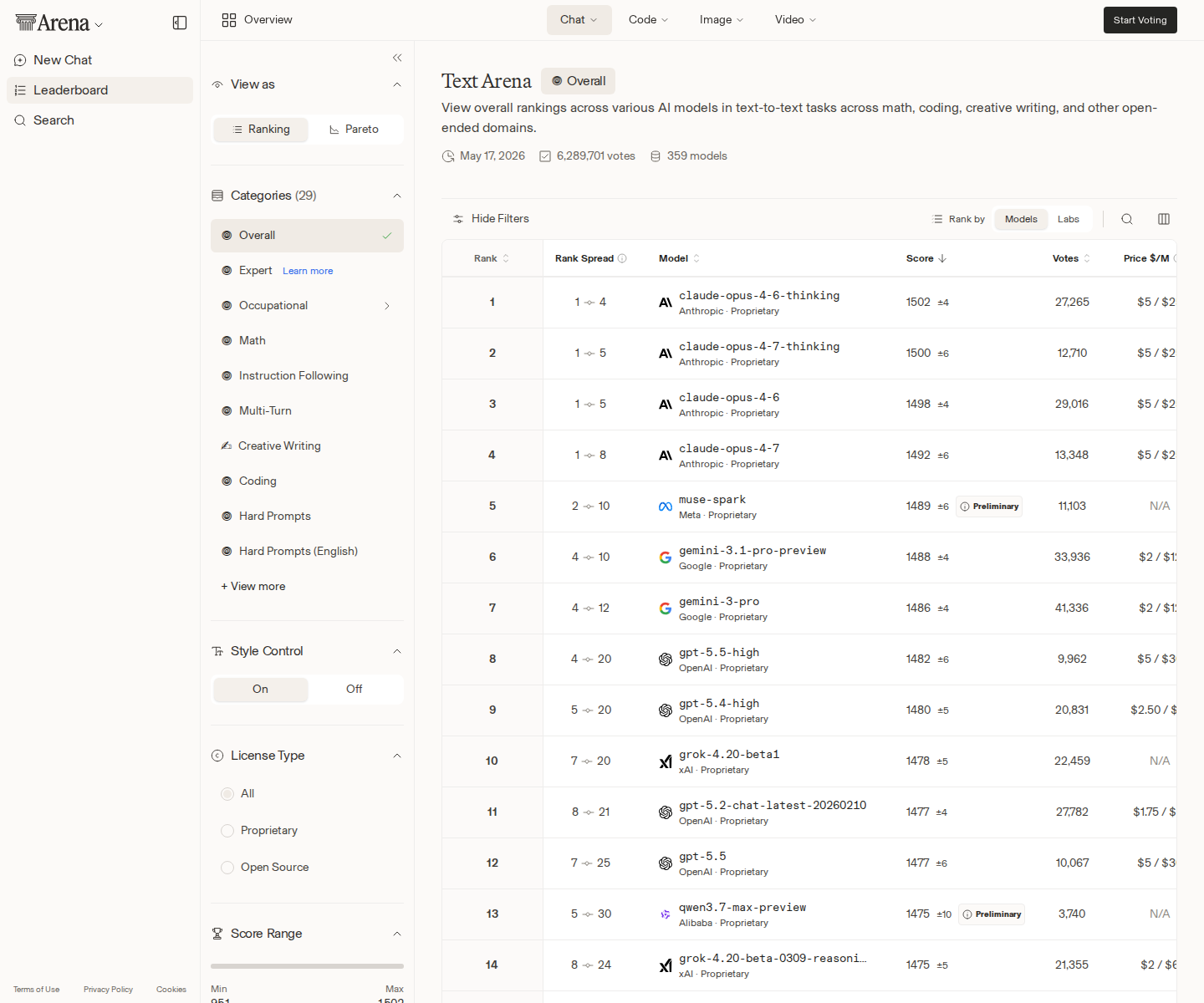
LM Arena did not move this week. That is the interesting part.
The public leaderboard most people treat as the prestige scoreboard is frozen at the top: Claude Opus 4.6 Thinking still sits at #1 on Arena AI Text with a 1502 Elo, Claude Opus 4.7 Thinking is #2 at 1500, and Claude Opus 4.6 without the thinking label is #3 at 1498. On the Code/WebDev board, Claude Opus 4.7 Thinking still leads at 1567 Elo. If your only signal is preference ranking, the story is simple: Anthropic remains extremely hard to dislodge at the top end.
But OpenRouter's usage board tells a more useful production story. Hy3 preview is still #1 with 2.66 trillion weekly tokens and a frankly loud +210% week-over-week jump. DeepSeek V4 Flash is still #2, rising from 1.86 trillion to 2.06 trillion weekly tokens, up 86% week over week. Claude Sonnet 4.6 passed Claude Opus 4.7 on usage — 1.55T tokens versus 1.54T — which is not a decisive win, but it is a tidy little reminder that the model engineers pick for the bill is not always the model that wins the demo.
The gap between those two boards is the thing to watch. Arena measures what people prefer in controlled comparisons. OpenRouter measures what people are actually routing tokens through. Neither is the whole truth, but one is closer to taste and the other is closer to infrastructure.
Usage is becoming the production leaderboard
Hy3 preview and DeepSeek V4 Flash are not dominating because everyone suddenly forgot frontier benchmarks exist. They are dominating because production systems reward a different bundle of properties: context length, price, throughput, tool behavior, and “good enough” reasoning at scale. OpenRouter's catalog describes Hy3 preview as a Tencent high-efficiency mixture-of-experts model for agentic workflows, with 262K context, configurable reasoning levels, tool support, and pricing around $0.066 per million input tokens and $0.26 per million output tokens. That is not a vanity spec. That is an invitation to run a lot of agent work without feeling every request in the monthly cloud bill.
DeepSeek V4 Flash is the more technically interesting workhorse. The model card describes it as a 284B-total-parameter MoE model with 13B activated parameters and a 1M-token context window. Microsoft Foundry positions it for low-latency, high-throughput scenarios: chat, high-volume content generation, classification, summarization, extraction, and real-time assistants. OpenRouter lists the paid route around $0.112/M input and $0.224/M output tokens, while Microsoft’s Foundry pricing is $0.19/M input and $0.51/M output. Either way, the message is clear: this is not trying to be the model you worship. It is trying to be the model you can afford to call all day.
That matters because most AI products are not one heroic prompt. They are pipelines. A real application might classify intent, retrieve context, summarize state, choose a tool, draft an answer, validate the result, and only then show something to a user. If every step hits the most expensive flagship model, the architecture is either a prototype or a margin problem waiting for finance to notice. The mature pattern is a model portfolio: a strong planner or judge for high-risk calls, a cheaper default for routine execution, and specialized long-context or coding models where they actually earn their keep.
The reshuffle below the top two is where engineers should look
The top of OpenRouter did not flip, but the middle moved enough to be useful. Claude Sonnet 4.6 climbed from #4 to #3, pushing Claude Opus 4.7 down to #4. Gemini 3 Flash Preview moved from #6 to #5, Kimi K2.6 slipped from #5 to #6, Owl Alpha rose from #9 to #8, and DeepSeek V4 Pro moved from #8 to #9. GPT-5.5 is now #16, gpt-oss-120b is #18, and two new entrants cracked the top 20: Gemini 3.1 Pro Preview at #19 with 414B tokens and +48% week over week, and Qwen3.6 Plus at #20 with 378B tokens and +99% week over week.
That is not random churn. It looks like developers widening their agent stacks. Gemini 3.1 Pro Preview brings Google's frontier reasoning story, multimodal support, structured outputs, tools, and a 1,048,576-token context window on OpenRouter, but at a meaningfully higher price point: roughly $2/M input and $12/M output. Qwen3.6 Plus is the sharper cost-performance question. Qwen claims a 1M context window by default, improved agentic coding, better multimodal perception and reasoning, and benchmark numbers including 78.8 on SWE-bench Verified, 61.6 on Terminal-Bench 2.0, 87.1 on LiveCodeBench v6, and 90.4 on GPQA. OpenRouter lists it around $0.325/M input and $1.95/M output, with tool support, structured outputs, and reasoning controls.
The feature to watch in Qwen is not just the benchmark table. It is preserve_thinking, an API option meant to retain prior-turn reasoning content in agentic tasks. Multi-turn agents often fail in the seam between calls: the model had a good plan one turn ago, then the next invocation loses enough implicit state to wander into nonsense. If Qwen's approach makes that seam less lossy in real workflows, it is more important than a leaderboard bump.
Community attention is lining up with that practitioner angle. The Qwen3.6 Plus launch drew 596 Hacker News points and 213 comments. Gemini 3.1 Pro drew an even larger HN footprint — 963 points and 914 comments — though that conversation sprawled across consumer and product reactions as well as developer use. DeepSeek V4 Flash got a more systems-shaped discussion through Sean Goedecke's post, “DeepSeek-V4-Flash means LLM steering is interesting again,” which reached 271 points and 75 comments. The signal is not that Hacker News is a market oracle. It is that the people who build with these models are paying attention when capability becomes cheap enough, local enough, or steerable enough to change architecture.
Long context is useful; it is not an excuse to stop engineering
The most dangerous number in this cycle is 1M context. DeepSeek V4 Flash, Gemini 3.1 Pro Preview, Qwen3.6 Plus, and Owl Alpha all sit in or near the long-context conversation. Owl Alpha, which moved to #8 with 895B tokens and +121% week over week, is listed by OpenRouter as a free long-context agentic model with 1,048,756 context and 262,144 max completion tokens. The caveat is hard to miss: the Hacker News listing was bluntly titled around “prompts logged / closed-source.” Low-engagement warning, high-relevance risk.
For practitioners, long context should be treated like a larger heap, not better software design. It lets you solve some classes of problems cleanly: large repositories, long contracts, support histories, migration plans, audit trails. It also lets teams dump unmodeled state into a prompt and pretend they built retrieval. That works until latency spikes, costs drift, or the model quietly attends to the wrong part of the haystack. The right question is not “can this model fit our entire repo?” It is “which parts of the repo should the model see, in what order, with what deterministic tools available when attention is not enough?”
If you run an engineering team using LLMs in production, the action item is boring and important: refresh your eval harness. Add Hy3 preview, DeepSeek V4 Flash, Qwen3.6 Plus, and Gemini 3.1 Pro Preview to the candidate set if your workload involves tools, long context, coding, summarization, or high-volume extraction. Do not replace your default model because OpenRouter usage moved. Route a representative slice of traces through each candidate and measure the things leaderboards do not: latency distribution, tool-call accuracy, instruction drift, structured-output validity, privacy posture, long-context retrieval accuracy, and human escalation rate.
Also split your evals by job. The model that is best for repo-scale patch generation may be wasteful for ticket triage. The model that is excellent at extracting fields from messy documents may be too sloppy for user-facing reasoning. The model that performs well interactively may have poor throughput economics in batch. A single “best model” spreadsheet is how teams accidentally turn model choice into office astrology.
The editorial read: Arena still matters for capability, but OpenRouter is becoming the better early-warning system for production behavior. When a cheap, long-context, tool-capable model moves trillions of tokens, it means builders are already testing the cost curve. Sometimes they are wrong. Sometimes they are just doing the work before the discourse catches up.
Claude still owns the prestige layer. OpenAI and Google are still very much in the fight. But the practical center of gravity is shifting from picking a champion to designing a router. The winning stack in 2026 will not be “we use Model X.” It will be “we know which model gets which job, and we have the evals to prove it.”
Sources: Arena AI Text Leaderboard, OpenRouter Rankings, OpenRouter model catalog, DeepSeek V4 Flash model card, Microsoft Foundry DeepSeek V4 announcement, Google Gemini 3.1 Pro announcement, Qwen3.6 launch, Sean Goedecke on DeepSeek V4 Flash steering