Microsoft Foundry Fine-Tuning Gets More Serious About Cost Control, Which Is What Production Teams Actually Needed

Microsoft’s latest Foundry fine-tuning update is not the kind of announcement that dominates the group chat. There is no flashy model name, no benchmark chest-thumping, no vague promise that everything is now agentic. What Microsoft actually shipped is more useful than that: cheaper global reinforcement fine-tuning for o4-mini, more flexible grader choices with GPT-4.1, GPT-4.1-mini, and GPT-4.1-nano, and a public best-practices push that basically admits the hard part of fine-tuning is not starting a job. It is avoiding expensive self-inflicted nonsense.
That is a good direction for Azure AI Foundry. The market has enough AI platform announcements written as if every team is one prompt away from product-market fit. Production teams do not need more theater. They need lower experimentation cost, clearer evaluation patterns, and fewer ways to burn money teaching a model the wrong lesson.
Cheaper training matters more than another model SKU
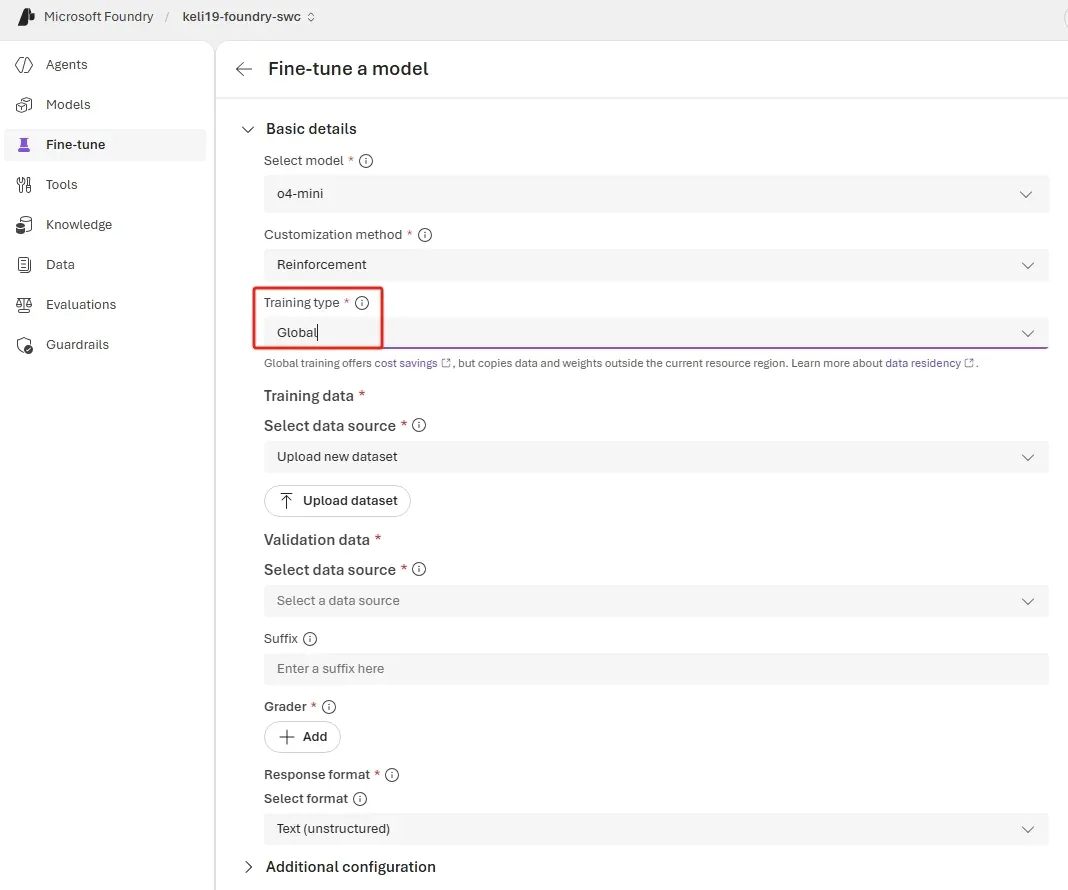
The headline product change is global training support for o4-mini. Microsoft says teams can now launch reinforcement fine-tuning jobs for o4-mini from more than 13 Azure regions, with broader finetuning-region coverage expanding by the end of April. The listed regions include East US 2, North Central US, West US 3, Australia East, France Central, Germany West Central, Switzerland North, Norway East, Poland Central, Spain Central, Italy North, Switzerland West, and Sweden Central.
The important part is not geography for its own sake. It is pricing and accessibility. Microsoft is explicitly positioning global training as a lower per-token alternative to standard training while keeping the same training infrastructure and model quality. That matters because reinforcement fine-tuning has a habit of sounding strategically important right up until the finance team sees the bill. Lowering the cost of early experimentation is how a platform moves RFT from “interesting lab capability” into “something a product team can justify trying this quarter.”
o4-mini is also the right model to emphasize. Microsoft calls it one of the most popular options for reasoning-intensive and agentic workloads, and that tracks with how teams are actually building. Most production systems do not need the most expensive model at every hop. They need something good enough to reason, route, classify, or call tools without turning every workflow into premium-token confetti. If Foundry can make the mid-tier reasoning model cheaper to customize globally, that is more strategically important than adding one more premium foundation model to a catalog page.
The graders are the product, whether people admit it or not
The second update is the addition of GPT-4.1, GPT-4.1-mini, and GPT-4.1-nano as model graders. Microsoft’s post is refreshingly direct here: graders define the reward signal, and the reward signal is what the model actually learns from. This sounds obvious, but a lot of fine-tuning discussion still treats evaluation like documentation you write after the clever part is done. In reinforcement fine-tuning, the grader is the clever part.
Microsoft’s guidance is sensible. Use deterministic graders first. Reach for model graders when the task is open-ended, subjective, or dependent on semantic context that string matching cannot capture. Start with GPT-4.1-nano for cheap iteration, move to 4.1-mini when the rubric stabilizes, and reserve full GPT-4.1 for higher-fidelity production scoring. That ladder matters because it turns grading from a binary choice into an economic design problem.
This is where the update gets genuinely useful for practitioners. A lot of teams want better tool use, policy adherence, or reasoning quality, but they do not have a reliable way to score those behaviors without either overpaying or introducing grading noise. Microsoft is effectively saying: use cheap graders while you are still figuring out what “good” means, and only spend more once the rubric deserves it. That is not glamorous advice. It is adult advice.
Foundry is trying to keep teams from reward-hacking themselves
The best part of the announcement is not a feature flag. It is the best-practices guidance around reward hacking, data format, and small-scale iteration. Microsoft recommends starting with 10 to 100 samples, using the simplest grader that works, changing one variable at a time, and watching reward trends before scaling up. That may sound conservative. It is also how you avoid teaching a model to pass a rubric while getting worse at the actual task.
The Learn documentation reinforces why this matters. RFT jobs are automatically paused once total training costs hit $5,000, covering both training and grading. That cap is a useful safety rail, but it also tells you something about the shape of the problem: reinforcement fine-tuning is expensive enough that Microsoft had to build a default brake into the service. This is not a toy feature. If your grader is noisy or your task design is sloppy, the platform will happily help you waste serious money faster than a prompt engineer can say “maybe it just needs more epochs.”
Microsoft’s examples also surface details teams routinely miss. In RFT data, the final message needs to be a user or developer role, not assistant. Extra fields used by graders have to match exactly across every data row. Structured-output grading requires a response format, otherwise your JSON references fail. None of this is sexy. All of it is the difference between a training loop that teaches the right behavior and one that produces a misleading graph plus a future incident.
This is really a platform-control story
There is a broader Azure angle hiding under the surface. Foundry has spent the last few months looking increasingly like a control plane for enterprise AI rather than just a place to rent models. Global training, model graders, evaluation guidance, MCP integration advice, and cost controls all point the same way. Microsoft wants teams to build once inside Foundry’s operational boundary, then iterate on model behavior without stitching together separate tooling for training, grading, monitoring, and deployment.
That is a smarter platform argument than another leaderboard claim. Enterprises do not usually fail at AI because they lack access to one more model. They fail because evaluation is fuzzy, cost visibility is weak, and tool-using systems behave differently in production than they did in demos. Microsoft’s fine-tuning update does not solve all of that, but it does show the company understands where the pain actually lives.
It also hints at a more uncomfortable truth for builders: most teams should not start with reinforcement fine-tuning at all. If your problem is formatting, tone, or basic response shaping, Microsoft is right to steer people toward prompt engineering, structured outputs, or supervised fine-tuning first. RFT is worth the trouble when correctness can be scored, when tool choice matters, or when policy-compliant decision quality is the real bottleneck. Otherwise you are bringing a very expensive wrench to a prompt problem.
So what should engineers do with this update? First, treat grader design as a first-class engineering artifact, not a sidecar. Second, test RFT on a narrow task with clear success criteria before promising broader platform wins. Third, use cheaper grading paths and smaller datasets to learn quickly, then scale only once the reward signal looks trustworthy. And fourth, keep a human eye on outputs throughout training, because a model that learns to satisfy the grader without satisfying the user is not aligned. It is just gaming your spreadsheet.
Microsoft’s fine-tuning news this month is valuable precisely because it is less ambitious than the average AI launch. It is not claiming that reinforcement fine-tuning suddenly became easy. It is saying Foundry is getting better at making the hard parts cheaper, more explicit, and slightly harder to misuse. For production teams, that is the kind of progress that actually ships.
Sources: Microsoft Foundry Blog, Microsoft Learn: Reinforcement fine-tuning, Microsoft Learn: Fine-tuning function calls