Microsoft's Self-Healing Azure AI Platform Post Is the Most Honest Answer to 'What Does GitOps Actually Look Like at Scale?'

There is a particular kind of infrastructure failure that every platform engineer eventually learns about the hard way: someone fixes something at 2 AM through the Azure Portal, it works, everybody goes to sleep, and three days later nobody can explain why the deployment registry says one thing while production says another. That gap between what git thinks is deployed and what is actually running is not a tooling problem. It is a trust problem. And it compounds faster than most teams realize until they are reconciling six months of portal clicks against a Terraform state that has no memory of them.
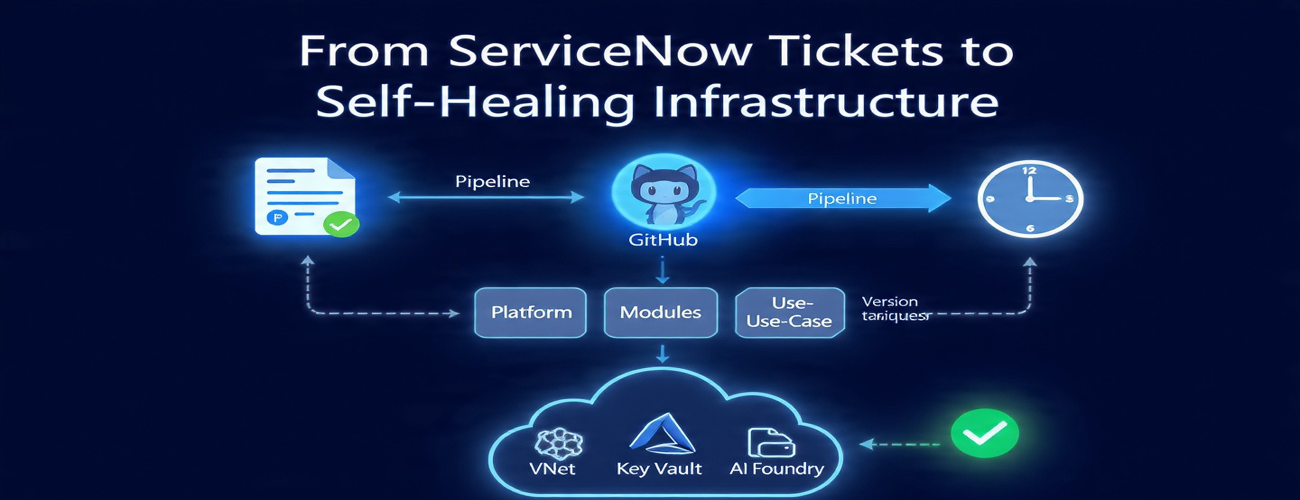
Microsoft published a detailed post-mortem this week from an engineer who has apparently lived this story more than once. The architecture they describe — three Terraform repos, five pipelines, 37 reusable modules, and a daily reconciliation system — is the response to that specific failure mode. It is also the most honest answer to "what does GitOps actually look like at scale?" that I have seen from a tier-1 vendor in some time.
The Two Drift Problems Nobody Talks About
The most useful thing in the post is the distinction between two categories of infrastructure drift that most platform teams conflate. Pipeline-level drift happens when someone runs terraform apply outside the official pipeline — maybe it was faster, maybe it was a one-off fix, maybe it was the 2 AM incident described above. The deployment registry does not update, but Terraform state does. From that moment on, your version tracker and your Terraform state disagree, and you have no automated way to know.
Portal-level drift is different. Someone clicks through the Azure Portal, changes an NSG rule, hits Save, and the world moves on. Terraform state does not know. The version tracker does not know. The next time your pipeline runs, it might overwrite that change, or it might not, depending on whether the pipeline touches that specific resource. You only find out when something breaks or when someone notices the mismatch during a code freeze retrospective.
The post describes building separate detection mechanisms for each. The reconciliation pipeline — running daily at 6 AM — catches pipeline drift by comparing the version tracker JSON (written by the pipeline after every deploy) against Terraform state serial and the central registry blob. If all three agree, the system is healthy. If they diverge, the reconciliation report names exactly what drifted and where. Portal drift is caught differently: by the next scheduled terraform plan run, which surfaces unexpected diffs, followed by an automatic terraform apply that reverts portal changes. No human action required for portal drift. The machine closes the loop on itself.
The practical implication for platform teams is that you cannot solve both problems with one mechanism. Most infrastructure-as-code tooling treats these as the same failure mode. They are not. Building for both — and being explicit about the distinction in your runbooks — is what separates platforms that stay coherent at scale from platforms that accumulate invisible debt at the corners.
The Version Pin That Actually Holds
The post describes an AVM-based module library with 37 reusable Terraform modules, all version-pinned using hard references like ref=avm-res-keyvault-vault/v0.10.2. This sounds like standard module management, but the author names the failure mode it prevents with unusual precision: if the same Key Vault definition lives in two places, it will diverge within three months. Not eventually. Within three months. One team updates it for their use case. Another team does not pull the change. Six months later you are debugging a policy mismatch that nobody can explain because the root cause is a version fork nobody acknowledged.
The pinned module approach is the correct architectural response, and the specificity of the version reference format matters more than it looks like it should. Semantic versioning tags in a shared module registry are not enough — they allow drift at the "latest patch" level. Hard refs like avm-res-keyvault-vault/v0.10.2 are not. Application teams cannot accidentally consume a newer module version without opening a PR, which means the version boundary is a governance boundary, not just a label.
For teams managing Azure estates across multiple business units or geographies, this pattern is worth stealing wholesale. The cost is the upfront investment in building and maintaining the module library. The return is a class of synchronization bugs that simply stops happening because the mechanism that caused them no longer exists.
The Three-Way Truth Table That Makes Reconciliation Work
The architecture uses three independent tracking records that cross-check each other: Terraform state serial, the version tracker JSON (written by the pipeline after every deploy), and a central registry blob containing one subscription.json per market. When all three agree, the system is healthy. When they diverge, the reconciliation report tells you exactly which record is wrong and by how much.
This is a underappreciated pattern in infrastructure automation: building a reconciliation system requires at least three independent sources of truth, not two. Two-way comparisons can tell you something is wrong but cannot tell you which system is authoritative. Three-way comparisons can. The tiered reconciliation logic in the post — Tier 1 when the version tracker exists, Tier 2 falling back to registry-to-state comparison for older environments, Tier 3 comparing timestamps with a five-minute tolerance for environments with no serials at all — is the kind of pragmatic backward-compatibility that most architecture documents leave out because it is messy. The fact that this post includes it makes it more credible, not less.
What This Costs and Who Should Pay It
The honest caveat in the post is about scale. Three repositories, five pipelines, 37 modules, daily reconciliation, and the engineering time to build and maintain all of it is not a small investment. The author does not put a dollar figure on it, but anyone who has built platform infrastructure will recognize the order of magnitude. For organizations below a certain size — single business unit, single geography, single team owning the whole estate — this architecture is overkill. The blast radius of drift in a small estate is limited enough that daily reconciliation is a nice-to-have, not a survival requirement.
The right audience is platform teams running Azure across multiple business units or geographies where the failure modes described in the post — an NSG change made at 2 AM that nobody remembers for three days — have non-trivial blast radius. In those environments, the investment in reconciliation tooling pays for itself the first time it catches a production incident that would otherwise have required a 2 AM war room to diagnose.
For smaller teams, the takeaway is the principle, not the exact implementation. Build the three-way tracking concept into your next platform design. Add the reconciliation run even if it is weekly. Use the portal drift detection pattern even if you do not have five pipelines yet. The specific architecture here is built for a large enterprise. The instincts it encodes are useful at any scale.