NotebookLM-Skill Suggests the Next Coding-Agent Memory Layer Might Be a Research Notebook, Not a Bigger Context Window

The easy answer to AI coding memory has been “just give the model more context.” It is a seductive answer because it looks like scale, and scale is the favorite religion of this market. Bigger window, more files, fewer manual summaries, problem solved. Except it does not really solve the thing teams are struggling with. Long sessions still drift. Important architectural decisions still disappear into scrollback. Project knowledge still gets trapped in transient chat threads. And when a new session starts, the model is still reconstructing the same background from scratch like a very expensive intern with amnesia.
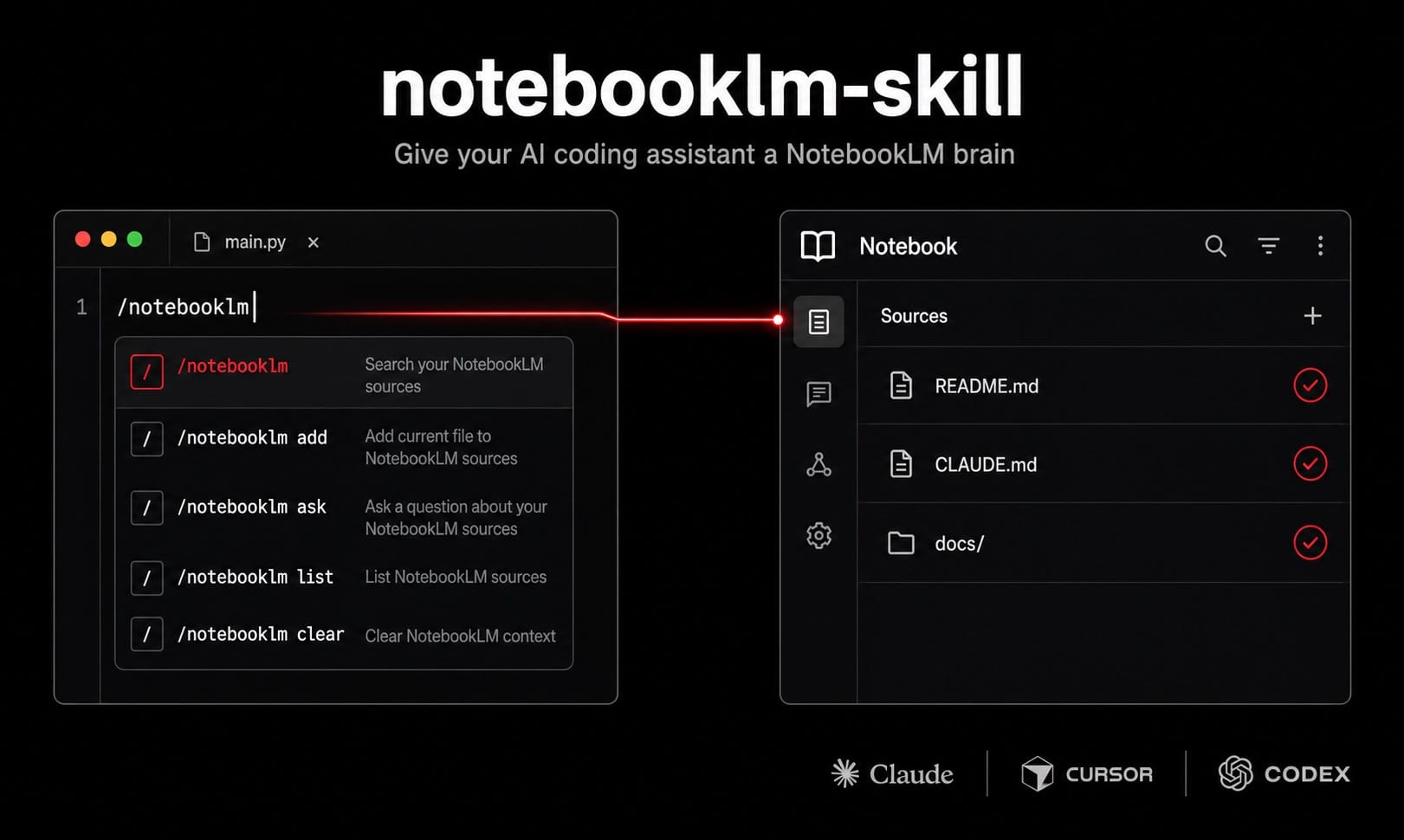
notebooklm-skill, created on April 26, is interesting because it rejects that framing. Instead of treating memory as an ever-larger prompt, the project treats it as an external, project-scoped research system. The repo wires Google NotebookLM into coding-agent workflows across Claude Code, Cursor, and OpenAI Codex through a two-layer design: a universal CLI for notebook creation, syncing, querying, and artifact generation, plus platform-specific skills or adapters that teach each agent how to use it. The details matter, but the more important idea is simpler: maybe coding agents need a notebook, not another context-window arms race.
The implementation is surprisingly concrete for a same-day repo. The project supports per-project notebooks via .notebooklm/config.json, a global registry mapping project paths to notebook IDs, source syncing for files and docs, question answering over the notebook, and a wrap-up flow that saves session logs back into the project memory. It also exposes NotebookLM’s artifact generation surface, including reports, quizzes, flashcards, slide decks, infographics, mind maps, and audio. Some of that is more useful than the rest. The audio podcast is cute. The notebook as a persistent synthesis layer for project context is the serious part.
That distinction matters because the AI coding market keeps confusing memory with storage. Storing more tokens is not the same as maintaining a useful, queryable, durable understanding of a system. What practitioners actually need is a place to accumulate architecture decisions, source documents, implementation notes, and session summaries in a form the next agent run can interrogate intelligently. NotebookLM is not the only candidate for that job, but it is an intriguing one because it is built for synthesis rather than raw retrieval.
Chat history is not a knowledge system
This is the deeper category critique embedded in the project. Chat history works as short-term interaction state. It is a terrible long-term project memory. It is linear when software understanding is relational. It is verbose where teams need distilled conclusions. It is hard to search, harder to curate, and prone to mixing settled facts with half-baked detours. When organizations say they want coding agents with memory, what they usually want is not an infinite transcript. They want a research notebook that gets smarter as the project evolves.
Notebooklm-skill is far from turnkey enterprise polish. The repo depends on an unofficial CLI, uses Playwright Chromium for authentication, and leans on browser-cookie state that can expire after a few days. That is not exactly the calm, boring infrastructure posture most companies dream about. But the product instinct is still stronger than much of the current competition. It assumes that memory should be explicit, searchable, project-scoped, and independent of any single vendor shell.
That last point is especially important. The project supports Claude Code, Cursor, and Codex, with partial or manual paths for other agents. That cross-platform ambition says something meaningful about where the market is going. Teams are unlikely to standardize on one shell forever. They will mix editor agents, terminal agents, hosted agents, and custom internal tooling. If project memory lives only inside one vendor’s session model, it becomes another lock-in vector and another source of discontinuity. An external notebook gives the workflow a shared brain even when the shells change.
There is a nice symmetry here with the broader harness-engineering conversation. As Martin Fowler and others have argued, useful agent systems are not just about a better model. They are about the surrounding scaffolding that narrows search, preserves intent, and keeps context from evaporating. Notebooklm-skill belongs to that class of tooling. It is not trying to make the model inherently smarter. It is trying to give it a better memory substrate.
The next memory layer may look more like research than retrieval
The more original implication is that coding-agent memory may end up looking less like a vector database and more like a living research notebook. Those are different philosophies. Retrieval systems are good at finding chunks. Notebooks are good at building understanding over time. In software work, both matter, but the second is underbuilt. Engineers do not just need to know where a file lives. They need to know why a decision was made, what alternatives were rejected, what constraints matter, what changed last week, and which assumptions remain shaky. Those are notebook questions.
Practitioners should pay attention because this directly affects agent reliability. A large share of “over-editing” and “wandering” behavior comes from agents improvising around missing project memory. If the only durable context is code plus whatever fits in the active window, the model fills gaps with plausible nonsense. External memory does not eliminate that risk, but it can sharply reduce it if the notebook is curated and the wrap-up discipline is real.
There are limits, of course. A notebook can also become a dumping ground. If every session summary is saved without synthesis, the memory layer turns into a mess with better branding. Teams adopting this style of workflow will need conventions: what gets promoted into the notebook, what stays ephemeral, how sources are versioned, and how contradictory notes are reconciled. Memory infrastructure does not remove the need for judgment. It makes judgment legible.
There is also a privacy and compliance angle. NotebookLM is a cloud product. Some teams will prefer local or self-hosted memory layers for sensitive work. That does not weaken the underlying thesis. It just means NotebookLM is one implementation path, not the final answer. The real takeaway is that project memory should be treated as a first-class layer in the agent stack, with clear ownership, boundaries, and retrieval semantics.
What should engineering teams do now? First, stop assuming bigger context windows are a memory strategy. They are, at best, a temporary patch. Second, create a deliberate project knowledge layer, whether with NotebookLM, internal docs, or another structured notebook system. Third, build session wrap-up into your agent workflow so useful conclusions survive past the terminal window. And fourth, keep memory project-scoped. Shared organizational lore is useful, but most coding mistakes happen when an agent lacks the specific local context that the code itself does not reveal.
The market keeps treating memory like a model feature. It is probably closer to infrastructure. Notebooklm-skill is rough around the edges, but it is rough in a productive direction. It suggests the next real leap in agentic coding may come from better external memory, not just more tokens shoved into a bigger box.
Sources: ibaifernandez/notebooklm-skill, Google NotebookLM, notebooklm-py, Martin Fowler on harness engineering