The Abstraction Layer Eating Itself: Hy3, Opus 4.7, and This Week's LLM Rankings

The Abstraction Layer Eating Itself
There's a delicious irony unfolding on OpenRouter's weekly rankings that nobody seems to be talking about. OpenRouter built its business on routing traffic away from proprietary APIs — a middleware layer that lets developers swap between OpenAI, Anthropic, Google, and whoever else without changing their code. The bet was: the abstraction layer is valuable because it sits between developers and the frontier models.
This week, Tencent's Hunyuan-derivative Hy3 preview rocketed to the #2 spot on OpenRouter with 1.38 trillion tokens processed in a single week. It's a net-new entry. There's also a second Hy3 instance sitting at #18 with 338 billion tokens, suggesting either multiple deployment endpoints or OpenRouter's traffic attribution doing something interesting with parallel instances. The combined Hy3 volume — 1.72 trillion tokens — would put it ahead of everything except Kimi K2.6's monstrous 1.99 trillion.
Here's the irony: OpenRouter is routing traffic away from proprietary APIs, and now a state-adjacent Chinese company's free preview model is routing traffic through OpenRouter. The abstraction layer is eating the abstraction layer. Tencent is using OpenRouter as a distribution vector to reach Western developers, and OpenRouter is happy to route that traffic because it looks great on their usage leaderboard.
For practitioners, the Hy3 story is worth tracking beyond the novelty. Free tier availability almost certainly explains the explosive volume — developers are trying it at zero cost, which means they're integrating it into their stacks. The question isn't whether Tencent has a competitive model (they clearly do). The question is whether you're comfortable routing production queries through a platform where usage data is being aggregated alongside every other model's traffic. There's a data sovereignty question lurking in here that most developers haven't thought through. When you call OpenRouter and OpenRouter routes to Tencent, where does your query data go?
The Volume vs. Quality Divergence
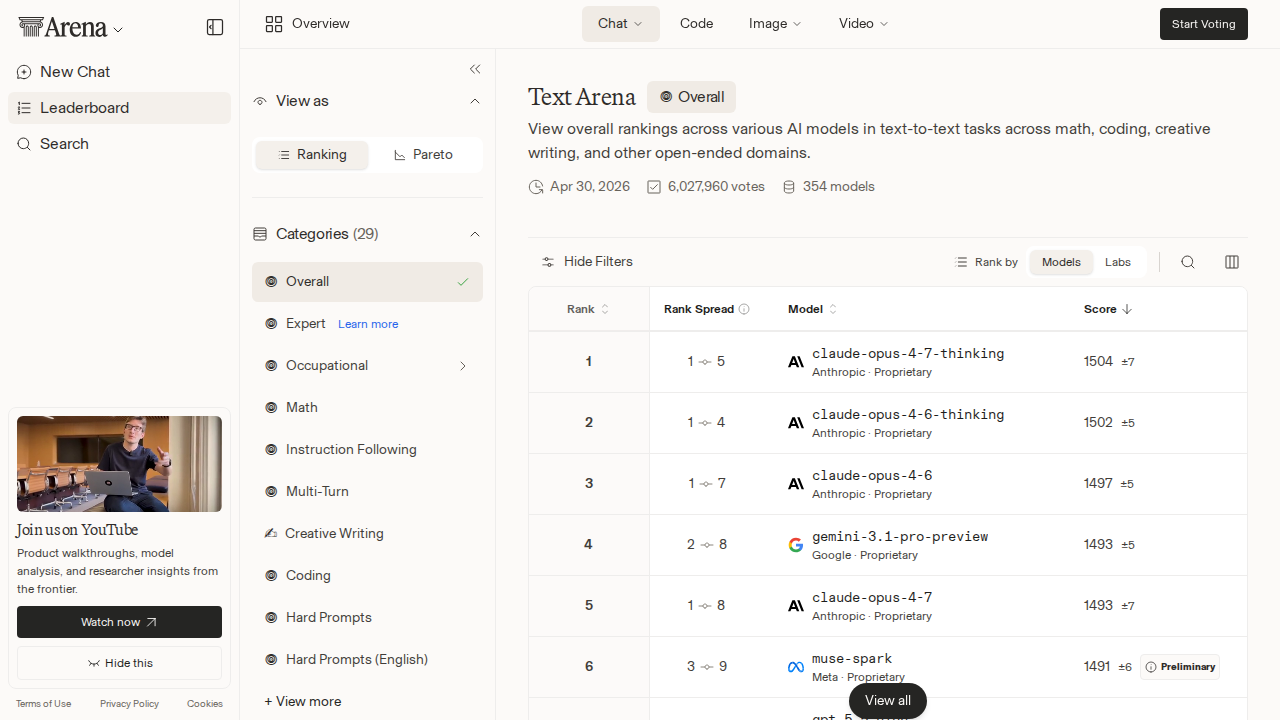
If the Hy3 story is about distribution, the Claude Opus 4.7 story is about something more fundamental: the growing gap between what benchmarks measure and what developers actually choose for production workloads.
Opus 4.7 climbed to #5 on OpenRouter this week, posting a 50% week-over-week surge to 1.13 trillion tokens. That's the kind of growth that turns heads. Yet on Arena AI's text leaderboard, Opus 4.7 sits at rank 4 with an Elo of 1495 — behind three thinking variants, two of which are Anthropic's own opus-4-7-thinking and opus-4-6-thinking. The thinking models are compressing the performance ladder into a tighter band, and Opus 4.7 — which would have been the undisputed frontier model six months ago — is now the "affordable option" in Anthropic's own lineup.
But developers are choosing it anyway. That's not a benchmark story. That's a production story. Opus 4.7 is earning its keep in real applications where the extra latency and cost of thinking variants isn't justified by marginal Elo gains. The benchmark ceiling has become so high that incremental improvements are indistinguishable to most tasks — and the real differentiation has shifted to cost-per-token, context window behavior, and specific task fit.
This is worth sitting with: Kimi K2.6 sits at #1 on OpenRouter with 1.99 trillion tokens and 303% week-over-week growth. It's not the best model by Arena benchmarks (it doesn't appear in Arena's top 10 for text). But for a significant chunk of developers, it's the model they're actually using. The leaderboard arms race and the production adoption war are increasingly two different things.
Arena: The Freeze at the Top
If OpenRouter is where the volume story plays out, Arena AI is where the benchmark obsessives look for signals. And this week's Arena data shows something interesting: the top of the text leaderboard has effectively frozen.
Anthropic's opus-4-7-thinking sits at 1503 Elo. Its opus-4-6-thinking sibling sits at 1502. That's a one-point gap. For context, Arena's margin of error on these scores is typically cited around ±5-7 Elo. Statistically, these models are tied. Anthropic has essentially deployed a versioning strategy where its own thinking variants compete with each other for the top spot more than with any external competitor.
The practical implication for developers: opus-4-7-thinking gives you the highest Elo; opus-4-6-thinking gives you nearly identical benchmark performance at what is presumably a lower cost and latency. The thinking variants are compressing what used to be a wider performance ladder into a tight band where model selection is increasingly about preference and price rather than measurable capability differences.
Meanwhile, in the code leaderboard, Anthropic dominates with seven of the top 10 entries. Kimi K2.6 holds sole possession of rank 6 with 1529 Elo — no longer tied with anything. But the real story in code is the concentration: Anthropic's models occupy the top four positions. The code benchmark race has become an Anthropic internal competition with Kimi as the sole credible external challenger.
What Practitioners Should Actually Do With This
The rankings tell a story, but the practical question is always: what should I actually use?
A few signals worth extracting from this week's data:
The free-tier model proliferation is real. Hy3 preview, Nemotron 3 Super (free), and others are using free access as a distribution strategy. If you're building prototypes or internal tools, these free tiers are worth evaluating seriously — not just for cost, but because some of them are genuinely competitive. The caveat is data handling: understand where your queries are going before you put real user data through a free preview model routed through a third-party platform.
The thinking vs. non-thinking choice is getting cheaper. With the top thinking models separated by 1-2 Elo, the marginal benchmark benefit of opus-4-7-thinking over opus-4-6-thinking is negligible. If you've been avoiding thinking models for cost or latency reasons, the calculus is shifting. The performance gap has narrowed to the point where the choice between thinking and non-thinking variants is more about task type than raw capability.
Volume doesn't equal quality for your specific use case. Kimi K2.6 at #1 on OpenRouter and Hy3 at #2 are worth watching, but Arena benchmarks and production preference don't always align. Run your own evals on your actual workloads before making routing decisions based on aggregate usage rankings. The 50% week-over-week growth in Opus 4.7 usage is a stronger signal for production adoption than a net-new entry displacing established models through free-tier volume.
The leaderboard picture is shifting faster than it was a month ago — new entrants, dramatic volume swings, Chinese labs competing directly on Western routing platforms. But the fundamentals haven't changed: benchmark performance, production cost, and task-specific fit are still the variables that matter. The rankings tell you what's moving. Your own evals tell you what to use.
Sources: OpenRouter Rankings, Arena AI Leaderboard