The Model That Won the Volume War (And the One That Bought It)

May 2, 2026
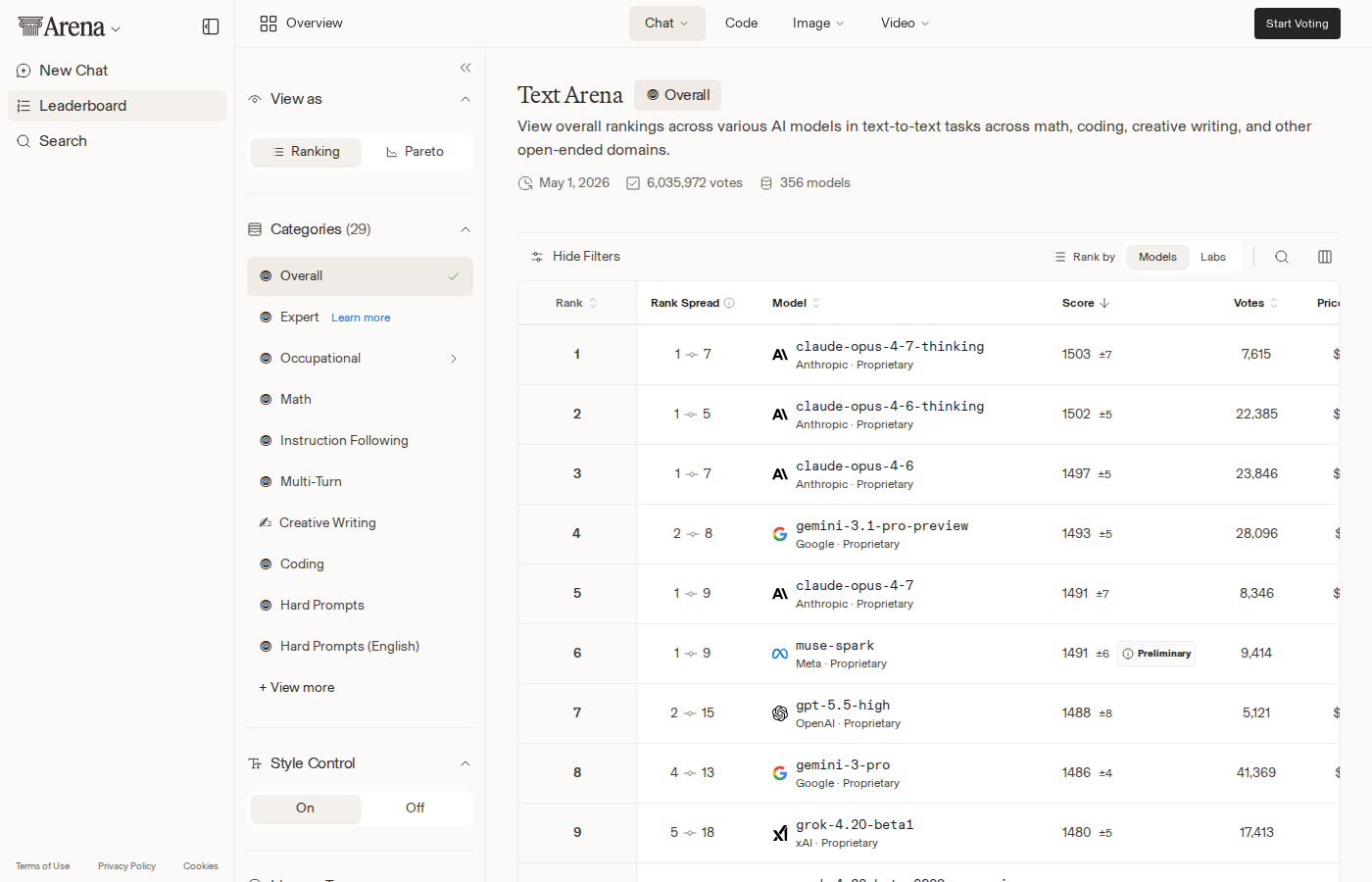
If you've been watching the LLM leaderboards lately and wondering why the model that tops the benchmark wars keeps losing marketshare to cheaper alternatives — today's data snapshot is for you.
The Arena Text leaderboard for May 1, 2026 reads like a coronation ceremony for Anthropic. Claude Opus 4.7 Thinking sits at 1504 Elo. Claude Opus 4.6 Thinking at 1502. The non-thinking Opus 4.7 at 1493. Three of the top five spots belong to the same family. Gemini 3.1 Pro Preview eked out a single-point gain to land at #4, which you'll notice only because the leaderboard makes you look. The coding rankings are even more lopsided — the top four slots are all Anthropic. If you were judging purely by Elo, you'd conclude that Anthropic has effectively closed the market.
Now look at OpenRouter's volume rankings for the same day.
Kimi K2.6 from Moonshot AI is processing 1.99 trillion tokens. That's up 303% week-over-week. It is not the best model on Arena. It is not the most expensive. It is, by the raw economics of who developers are actually paying to run inference at scale, the most successful model in the world right now. Tencent's Hy3 Preview — free, subsidized, brand new — sits at #2 with 1.38 trillion tokens. Two Tencent instances in the top 20, neither of which existed a week ago. Meanwhile, Claude Sonnet 4.6, Anthropic's own #3 on OpenRouter, has "held" position with a 2% weekly gain. In what world is 2% a hold when the competitor next to you is doing 303%?
The world where quality and economics are telling completely different stories, that's where.
The Architecture Behind the Price
K2.6 is a mixture-of-experts model. One trillion total parameters, but only 32 billion activate per forward pass. That distinction matters enormously when you're running inference at scale. You pay for the compute you actually use, not the parameters you theoretically have. This is why K2.6 can price itself at $0.57 per million prompt tokens and $2.30 per million completion tokens on OpenRouter while still generating enough margin to fuel 303% volume growth. The architecture makes it viable to be aggressive on price. The price makes it viable for developers to switch.
What's worth noting is that Moonshot is running a dual-variant strategy that shows real sophistication. Kimi K2.6 sits at #1 on OpenRouter with 1.99T tokens. Kimi K2.5 — presumably the less capable, lower-priced sibling — sits at #20 with 313B tokens and 20% weekly growth. Two models, two price points, both in the top 20. They're not trying to win one segment. They're trying to own a spectrum.
The Arena code rankings tell a complementary story. K2.6 ranks #6 in coding capability at 1529 Elo. Ahead of it: four Anthropic models and GLM-5.1 from Z.ai at 1534. Nobody is confusing K2.6 for the best coding model money can buy. But for developers building workflows where "good enough" plus "cheap plus fast plus long context" beats "marginally better but three times the cost," K2.6's 131K context window and MoE economics are a compelling combination. This is the mid-range sedan winning the race not because it's the fastest car but because most people need to get somewhere affordable and reliably.
The Free Tier Play
Tencent's entry into the top tier via a free tier is the most naked market penetration move in this week's data. Two Hy3 Preview instances, both free, combining for roughly 1.7 trillion tokens in a single week. This is not organic adoption. This is a deliberate subsidy designed to get developers to build workflows around a Tencent-deployed model before the free tier expires or the paid tier prices normalize.
Google did the same thing with Gemini Flash models. Get in cheap, get the adoption, then tighten pricing once you've got the developer lock-in. It's the razor-and-blades playbook adapted for API infrastructure. The interesting question for practitioners isn't whether the free tier will go away — it will — it's whether the quality of Hy3 Preview justifies the eventual paid tier pricing once you're already running it in production. Right now, you're essentially in a free trial. That's fine as long as you have a plan for what happens when the trial ends.
One thing worth flagging: the dual-instance deployment (1.38T at #2, 338B at #18) suggests Tencent is running at least two separate inference clusters or endpoint configurations. The difference in volume is almost exactly 4x, which could indicate different rate limit tiers, different model configurations, or simply different customer segments being routed to different endpoints. Either way, two instances means this isn't a hobby project — it's a production push.
The Divergence Is the Story
Here's the thing nobody writing breathless "X model wins AI" headlines is telling you: the two major data sources are measuring fundamentally different things, and right now they're giving you opposite answers.
Arena is a quality signal. It's human preference data, Elo-rated, reflecting which model a panel of testers prefers when shown outputs side-by-side. By that measure, Anthropic is dominant. Four of the top five in text. Four of the top five in code. That dominance is real and it matters — if you're building a system where errors are expensive, where the cost of a bad output is higher than the cost of a more expensive model, the Elo data is the right signal for you.
OpenRouter volume is an economics signal. It reflects what developers are actually running at scale, which is driven by a complex interaction of price, latency, context length, rate limits, and — yes — quality, all bundled together. By that measure, Kimi K2.6 and Tencent's free tier are winning the volume game against Anthropic's premium pricing. Developers are making rational economic decisions: use the most expensive model for the highest-stakes tasks, use the cheaper model for everything else. That's not a knock on Claude — it's just a different market segment.
The gap between these two signals has been widening. Six months ago, the Arena top 10 and the OpenRouter top 10 had substantial overlap. Today, the quality leaderboard and the volume leaderboard barely agree on who's #1. This matters for practitioners because it means you can't look at one and conclude the other. If you're choosing models based on benchmarks alone, you're missing the economics. If you're choosing based on volume alone, you might be building on a free trial that'll expire.
What You Should Actually Do With This
A few practical takeaways from this week's data:
If you're building high-volume, cost-sensitive workflows — RAG pipelines, document processing, content generation at scale, anything where errors are recoverable — the OpenRouter volume data is your friend. K2.6's MoE economics and 131K context make it worth serious evaluation. The 303% growth isn't random; developers don't move that volume without a reason.
If you're building high-stakes production systems — code generation that ships to production, compliance-sensitive outputs, anything where a bad answer has real consequences — the Arena Elo data is still the right signal. The premium pricing on Claude variants reflects genuine capability differences on hard tasks. "Good enough" is not a virtue when the cost of failure is high.
If you're evaluating Tencent's Hy3 — treat the free tier as a migration pilot, not a permanent infrastructure decision. You should have a paid-tier evaluation plan ready before you go deep on integration, because the economics will change. The free trial is the carrot. The eventual pricing is the stick.
Watch for when these two data streams start agreeing again. Right now the market is bifurcating between "best" and "cheapest." Historically that tension resolves one of two ways: either the best gets cheaper (Anthropic reducing prices to compete on volume), or the cheapest gets better (Kimi closing the Elo gap). Either shift is a significant signal for how the market structures itself long-term.
The leaderboard wars will keep generating headlines. But the real story this week is the one hiding in plain sight: the models that developers actually run, at scale, in production, look different from the models that win benchmark tournaments. Both facts are true. The trick is knowing which one applies to what you're building.
Sources: OpenRouter Rankings, LMArena.ai Leaderboard, Kimi K2 on OpenRouter