The Plateau Hypothesis: Why the Arena Rankings Froze This Week

Something strange happened to the LLM leaderboards this week: they stopped moving.
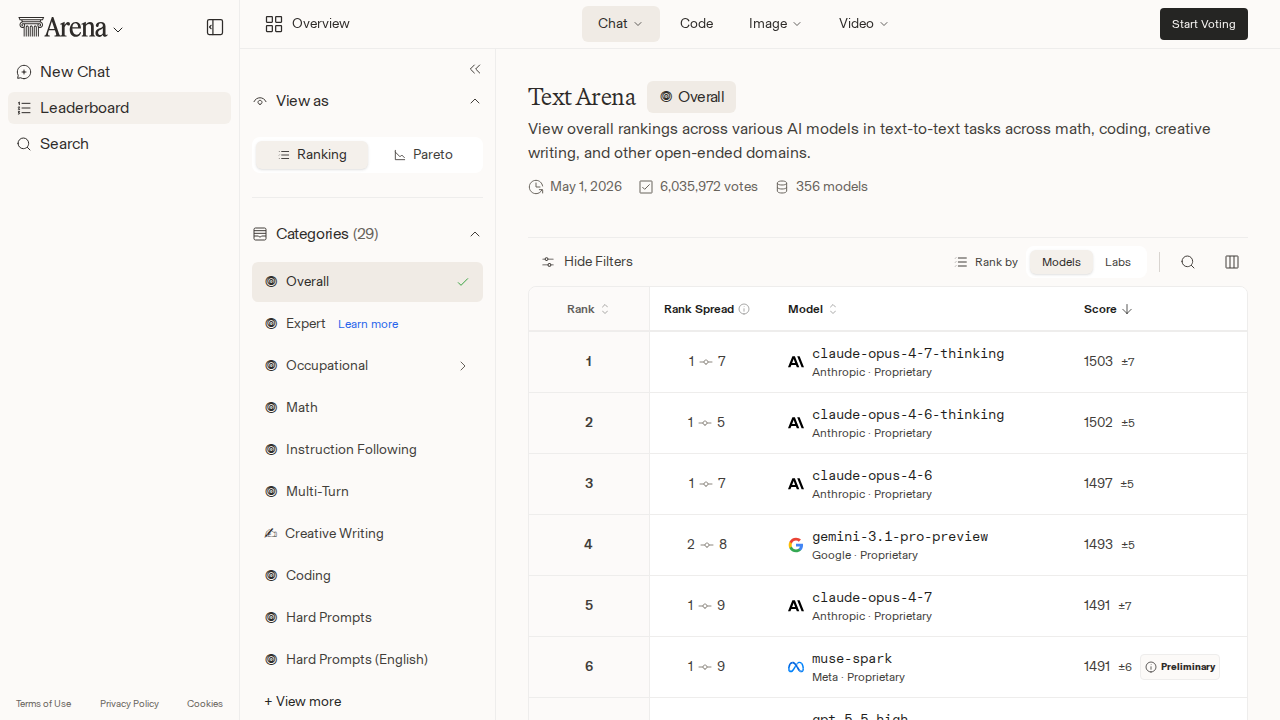
Both Arena AI leaderboards — text and code — showed zero change from yesterday. Same models. Same Elo scores. Same order. No movement at all. If you've been following these rankings, you know how unusual this is. Arena typically registers small shifts daily even when the overall hierarchy holds. The fact that every single score locked in place suggests one of two things: either the top frontier models have genuinely converged on performance, or we've hit a reporting artifact moment where the votes just aren't flowing enough to move integer Elo values.
My money is on the convergence hypothesis — and if that's right, it's more significant than it looks.
When a leaderboard freezes, the instinct is to call it a data issue and move on. But consider what convergence at the top actually means. Arena works by pairing models head-to-head and letting human voters pick the better response. For rankings to be static, you need either genuinely equal performance or insufficient voting volume to register marginal differences. Given that these models collectively process trillions of tokens per week and have been under continuous evaluation pressure, the idea that they're all just stuck at the same capability level is the more interesting story.
That story has a name: the plateau hypothesis. We've heard rumblings of it for months — the narrative that raw capability improvements on general tasks are flattening out, that the next frontier is efficiency, specialization, and cost. If the Arena freeze is real, it's the most visible evidence yet that the general intelligence race may be entering a holding pattern while the battlefield shifts elsewhere.
Meanwhile, the OpenRouter usage rankings told a completely different story this week — and that dissonance is itself the lead.
The Quality Contest vs. The Volume Contest
GPT-5.5 fell off a cliff on OpenRouter. Not in terms of quality — the model still sits at #7 on Arena Text (1488 Elo) and #9 on Arena Code (1492 Elo). But in terms of actual API usage volume? GPT-5.5 dropped from approximately 1 trillion tokens processed last week to around 520 billion this week, falling from #4 to #15 on the OpenRouter leaderboard. That's a roughly 50% collapse in reported volume within 24 hours, accompanied by a collapse in week-over-week growth from 26,044% (a launch-spike number) to a more mundane 8%.
What's going on? The most likely explanation is that OpenRouter's volume metrics work differently for first-party versus third-party API providers, and GPT-5.5's surge last week was either a promotional spike normalizing, or a reclassification of which variant's traffic gets counted. But here's the thing: the data is opaque enough that nobody outside OpenRouter can say for certain.
This is the part that matters for practitioners. The OpenRouter leaderboard is useful for macro-trend analysis — watching which families of models are gaining or losing ground over weeks and months. But for micro-optimization decisions? A model that can swing five positions in 24 hours on volume metrics while its quality scores stay flat tells you that these numbers aren't reliable enough to base infrastructure decisions on. If you're picking a model because it's #4 on OpenRouter this week, you might be building on sand.
The Arena scores, by contrast, are more stable by design — they're based on controlled pairwise comparisons with human voters, not raw traffic volumes that can spike and collapse with promotional cycles or billing reclassifications. The practical takeaway: watch Arena for quality signal, OpenRouter for usage trends, and treat neither as a precise targeting tool.
DeepSeek's Quiet Surge
If GPT-5.5's week was defined by dramatic collapse, DeepSeek's was defined by dramatic ascent. DeepSeek V4 Flash entered the OpenRouter top 10 this week at #9 with 671 billion tokens processed and a 769% week-over-week growth rate — one of the most explosive surges on the board. Meanwhile, DeepSeek V3.2 held steady at #5 with 948 billion tokens. Combined, DeepSeek is now processing roughly 1.62 trillion tokens per week on OpenRouter alone, with both models in the top 10.
The 769% growth number is eye-catching, but it's worth contextualizing. DeepSeek models have been available on OpenRouter long enough that a single promotional event or pricing change could produce a surge that looks enormous on a percentage basis while representing a relatively modest absolute volume in context. 671 billion tokens is real scale — it's roughly 60% of GPT-5.5's current volume — but it's not clear how much of this is new adoption versus redistribution of existing DeepSeek users onto OpenRouter as a routing layer.
What's less ambiguous is the strategic picture. DeepSeek has consistently positioned itself as the cost-conscious alternative in the LLM market — competitive performance at meaningfully lower prices. Their dual-model strategy (Flash variants for high-volume, standard variants for higher-complexity tasks) mirrors what Google has done with Gemini, and it reflects a broader market maturation: the modelProviders that will win the next phase aren't necessarily the ones with the highest capability scores, but the ones that can deliver acceptable quality at a price point that makes high-volume applications economically viable.
For builders, DeepSeek's rise is a useful reminder not to write off entire model families based on geopolitical assumptions. The research coming out of DeepSeek has been genuinely strong, and their pricing structure represents a structural advantage in markets where cost-per-token drives adoption. "Just a Chinese lab" is increasingly an inadequate summary of what DeepSeek is building.
The Two Rankings, Side by Side
Here's what strikes me most about this week's data: the divergence between the Arena picture and the OpenRouter picture is more pronounced than usual. Arena says Claude Opus 4.7 and its thinking variants dominate — Anthropic holds 7 of the top 10 text positions and 9 of the top 10 code positions. OpenRouter says Hy3 preview from Tencent is processing more tokens than anyone, followed by Kimi K2.6 and Claude Sonnet 4.6, with Anthropic's flagship model at #6.
What's the explanation? Arena voters are disproportionately engaged, technical users making deliberate comparisons. OpenRouter traffic reflects actual production usage patterns, which skew toward cost-sensitive applications, high-volume inference tasks, and builders optimizing for economics rather than peak quality on every call. These are different user populations with different selection criteria, and they legitimately disagree about which model is "best."
That disagreement is useful. It means you can't just pick the top-ranked model from a single source and call it done. The right model for your application depends on whether you're optimizing for quality, cost, latency, or some weighted combination — and the leaderboards that try to boil all of that into a single number are, by necessity, losing information in translation.
The Arena freeze is the story of the week. The OpenRouter churn is the story of the week. They don't agree with each other, and they shouldn't. The models at the top of each ranking are different because they're measuring different things. The builders who internalize that distinction will make better infrastructure decisions than the ones who just look at a number and move on.
One more thing worth watching: Hy3 preview processing 2.59 trillion tokens with 1081% week-over-week growth is not a small-data story. That's a number that suggests significant real-world deployment at scale. Whatever Hy3 is doing differently this week — whether it's a promotional price cut, a new integration, or genuine adoption — it's a signal worth tracking. The volume contest and the quality contest don't always produce the same winner. Sometimes they don't even agree on the game being played.
Sources: Arena AI Leaderboard, OpenRouter Rankings