Azure Blob Storage Wants to Kill the LLM Cold-Start Tax

The least glamorous Azure AI update this week is also one of the most useful. Microsoft and Run:ai added Azure Blob Storage support to Run:ai Model Streamer, which lets vLLM and SGLang stream SafeTensors model weights from az:// paths toward GPU memory instead of first downloading the full model to local disk. Translation: fewer expensive accelerators sitting idle while bytes take the scenic route.
This is the sort of infrastructure change that will not dominate a keynote and might actually improve production systems. Everyone wants to talk about frontier-model quality. Platform teams eventually talk about cold starts, queues, retries, saturation, and cost per ready replica. The model is the fancy part. The waiting is often the expensive part.
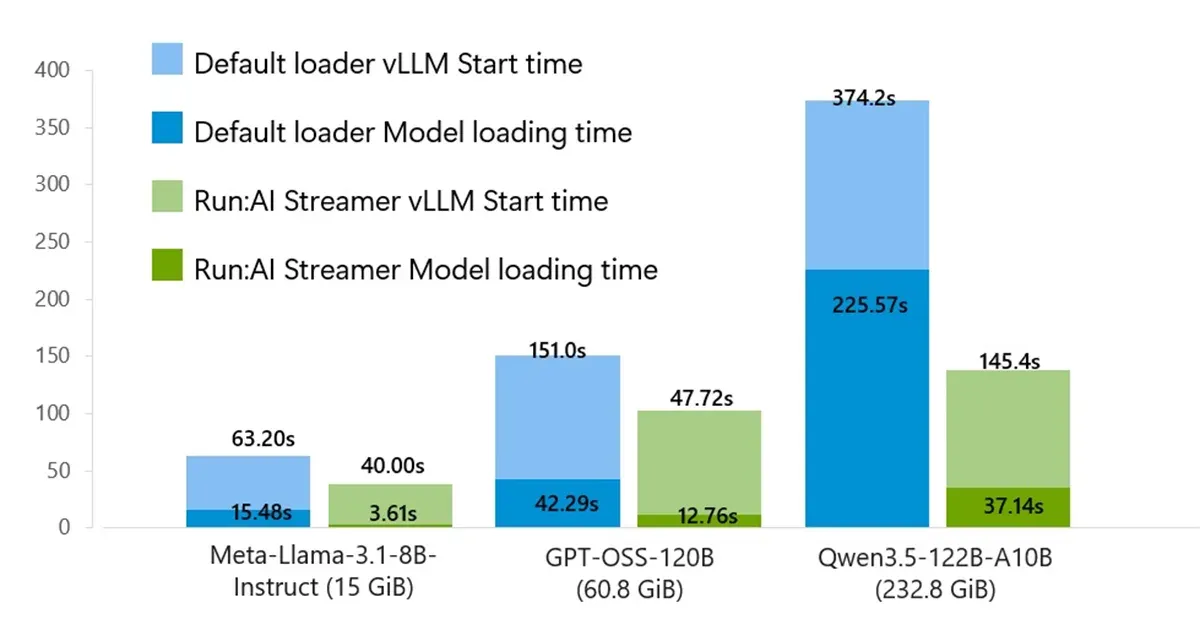
Microsoft’s benchmark is not subtle. On an Azure Standard_ND96isr_H100_v5 VM with 8 NVIDIA H100 80GB GPUs, 96 vCPUs, 1,900 GiB of system memory, 8 local NVMe SSDs totaling 28 TiB, NVLink 4.0, and 80 Gbps Ethernet, Run:ai Model Streamer produced 3x to 6x faster cold model loads than the default vLLM loader. The largest tested model, Qwen3.5-122B-A10B at 232.8 GiB, dropped from 225.57 ± 81.00 seconds to 37.14 ± 0.79 seconds. That is not a rounding error. That is the difference between autoscaling helping during a spike and autoscaling arriving after the incident has already filed itself.
The cold-start tax is a systems problem, not an AI problem
A conventional cold start often does the obvious but wasteful thing: fetch weights from object storage to local disk, then load them from disk into GPU memory. During that time, the GPU is allocated but unavailable. In a cloud bill, that means you are paying for the accelerator while it performs the emotional labor of waiting for storage. In an incident, it means traffic keeps queuing, retries multiply, and autoscalers may decide to add even more replicas that are also not ready yet.
The Run:ai approach attacks the extra staging step. Microsoft says the streamer maintained steady 80 Gbps throughput in its tests, while the default loader peaked around 40 Gbps and sometimes fell to roughly 10 Gbps on the largest model. The benchmark used a Premium block blob account with locally redundant storage in the same South Africa North region, and each model/loader configuration ran five times under cold-start conditions with the Hugging Face cache cleared. Load time was measured from vLLM logs when all model weights were resident in GPU memory.
The smaller numbers are useful too. Meta-Llama-3.1-8B-Instruct, a 14.99 GiB model, loaded in 3.61 ± 0.17 seconds with Run:ai Streamer versus 15.48 ± 8.69 seconds with the default vLLM loader, about 4.3x faster. GPT-OSS-120B, at 60.8 GiB, loaded in 12.76 ± 1.11 seconds versus 42.29 ± 25.96 seconds, about 3.3x faster. The pattern is the point: once model weights become large enough that startup time is mostly a byte-moving exercise, the storage path becomes part of the serving architecture.
Autoscaling only works if capacity arrives while the signal is still useful
The production implication is bigger than “startup is faster.” Autoscalers often operate on 30-to-60-second decision cycles. A 37-second load for a 233 GiB model can plausibly bring capacity online inside one or two control-loop windows. A 226-second load cannot. By the time the slow replica is ready, the traffic spike may have already caused timeouts, triggered retries, and pushed the autoscaler into an overcorrection. That is how systems get expensive and unreliable at the same time, which is the least charming combination in cloud computing.
This is why the Azure Blob integration matters even for teams that do not care about Run:ai branding. It moves open-model serving closer to the operational behavior people expect from normal services. If your inference stack takes minutes to become useful, it is not really elastic in the practical sense. It is merely eventually larger. Fast weight streaming does not solve every startup problem, but it removes one of the dumbest bottlenecks from the critical path.
There are caveats, because infrastructure benchmarks are not magic spells. Microsoft tested same-region Premium Blob storage, a high-end H100 VM, SafeTensors weights, cold cache conditions, and specific vLLM behavior. Your mileage will vary with region placement, storage tier, network path, shard layout, tensor parallelism, framework initialization, CUDA behavior, tokenizer/config loading, health-check design, and credential setup. Streaming weights also does not eliminate the need to validate model readiness, warm kernels, or handle framework-specific initialization. It makes the byte path better. It does not repeal physics.
The integration is practical enough to benchmark now
The good news is that this is not a research-only trick. vLLM supports installing the Run:ai optional dependency and serving directly from Azure Blob with a command shaped like vllm serve az://<container>/<model-path> --load-format runai_streamer. SGLang’s object-storage documentation lists Azure Blob alongside Amazon S3, Google Cloud Storage, and S3-compatible storage, using runai_streamer with a two-phase approach: metadata files are downloaded to local cache, while model weights are streamed from object storage during load.
Authentication also lands in the right place. The Azure integration uses DefaultAzureCredential, including az login, managed identity, and environment-variable credentials. That matters because production teams do not want storage keys scattered across Kubernetes secrets, shell histories, and notebooks like confetti. Managed identity support makes this plausible on AKS, Azure Machine Learning, and VM-based deployments without inventing another secret-handling ritual.
The one hard requirement teams should notice is SafeTensors. Microsoft explicitly warns to use .safetensors weights rather than relying only on .bin files. That is not just a format footnote. If your model registry, conversion pipeline, or vendor import process does not preserve SafeTensors artifacts cleanly, you may need to fix that before the streaming path becomes useful.
The action item is simple: measure your cold starts like you mean it. Start with replica creation to first successful inference, then break that timeline apart: container startup, framework initialization, weight transfer, GPU load, tokenizer/config handling, warmup, health-check readiness, and first-token latency. If weight loading is a large slice, test Azure Blob plus Run:ai Model Streamer with your actual model sizes, regions, storage accounts, and serving framework. If weight loading is not the bottleneck, congratulations: you found a different problem with evidence instead of vibes.
There is a broader industry lesson here. Open-model serving is becoming an infrastructure discipline, not just a model-selection exercise. The teams that win will not be the ones with the prettiest benchmark slide. They will be the ones that can move weights efficiently, scale predictably, attribute cost per ready replica, avoid retry storms, and keep GPUs doing useful work instead of waiting for a local disk staging step that should not have been on the hot path.
Azure Blob getting a direct path into vLLM and SGLang is Microsoft meeting production AI where it actually hurts: storage plumbing, network throughput, and control-loop timing. Boring? Absolutely. Useful? Also absolutely. If teams want open models to behave like production services, cold-start time is a first-class metric. Ship the plumbing.
Sources: Microsoft Azure SDK Blog, Run:ai Model Streamer, vLLM runai_streamer documentation, SGLang object-storage documentation