Copilot Cloud Agent Gets Cheaper Models Because Not Every Task Needs a Sledgehammer

The most mature AI-coding announcement this week may be the one that says, effectively, please stop using the expensive hammer for every nail. GitHub added Claude Haiku 4.5 and GPT-5.4 mini to Copilot cloud agent with a 0.33x multiplier, which is less a model-drop story than a sign that agentic coding is becoming a routing and cost-control problem.
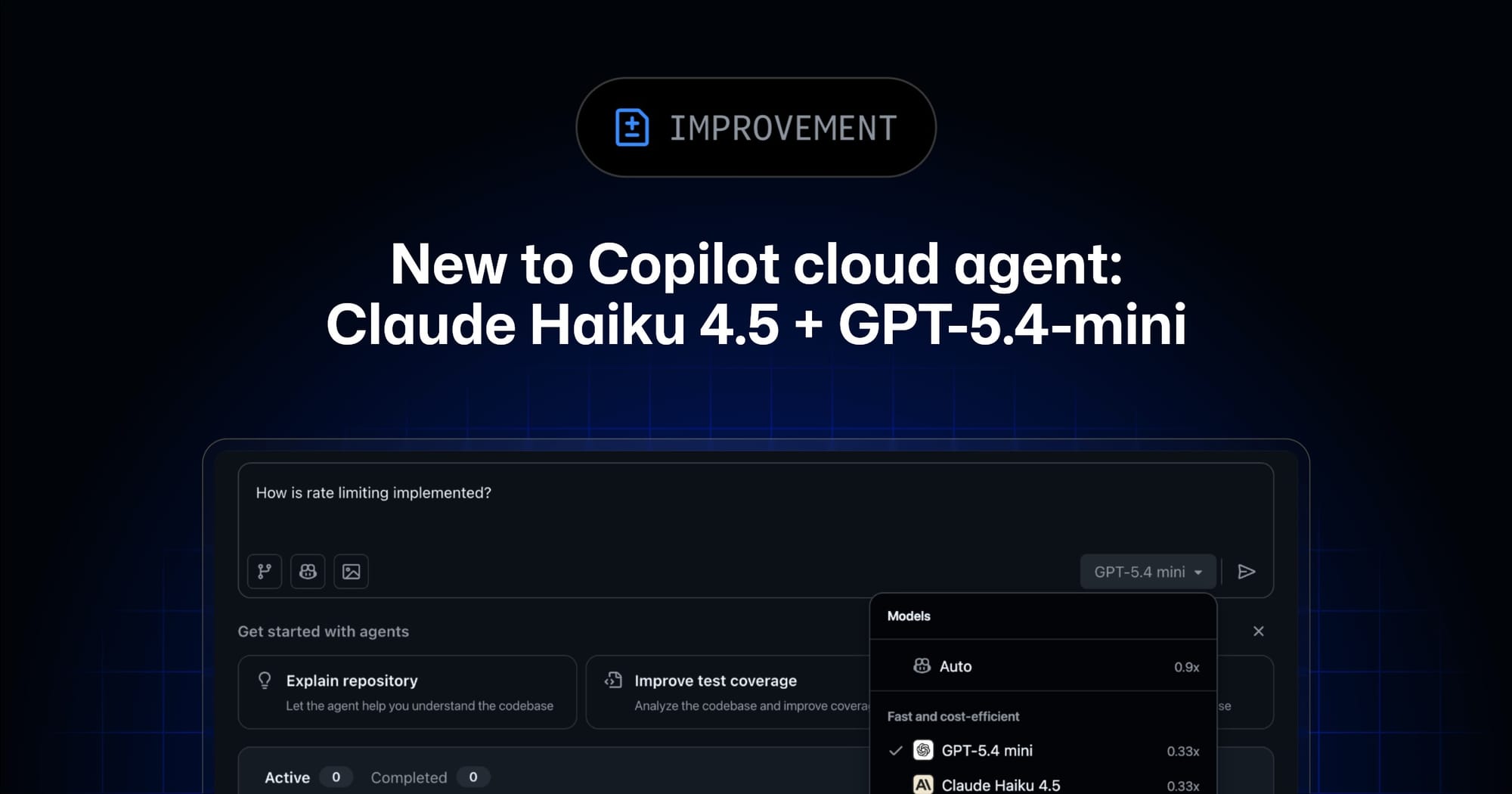
GitHub expanded Copilot cloud agent model selection with two cheaper/faster options: Claude Haiku 4.5 and GPT-5.4 mini, both listed with a 0.33x multiplier. The docs now show the current model menu as Auto, Claude Sonnet 4.5, Claude Opus 4.7, Claude Haiku 4.5, GPT-5.2-Codex, and GPT-5.4 mini. The strategic move is obvious: GitHub wants enterprises to route agent work by task class, not burn premium models on lint fixes and tiny refactors.
The 0.33x multiplier is a policy hint
The specific details are what make this more than another model-dropdown or agent-button story:
- New Copilot cloud agent model options: Claude Haiku 4.5 (0.33x multiplier) and GPT-5.4-mini / GPT-5.4 mini (0.33x multiplier).
- GitHub positions the new models as “faster, more cost-efficient options” for straightforward changes.
- Current documented model choices: Auto, Claude Sonnet 4.5, Claude Opus 4.7, Claude Haiku 4.5, GPT-5.2-Codex, and GPT-5.4 mini.
- Model selection is supported when assigning an issue to Copilot on GitHub.com, mentioning `@copilot` in a pull request comment, or starting a task from the agents tab, agents panel, GitHub Mobile, or Raycast.
- Where no model picker is available, GitHub says Auto is used automatically.
- GitHub’s docs say Auto selects based on availability and rate-limit reduction, which makes model choice both a quality control and capacity-management mechanism.
- This source is official GitHub changelog/docs; no aggregator source was used.
This is the cost-control chapter of agentic coding becoming real infrastructure. Once agents move from autocomplete to background work, model choice stops being a taste preference. A small test fix, a generated migration plan, a cross-repo architectural refactor, and a security-sensitive code review should not automatically hit the same model tier. The engineering problem is routing.
The 0.33x multiplier is the tell. GitHub is giving enterprises a financial reason to classify work. Simple chores can use smaller models; deep debugging and ambiguous design work can use stronger ones. That sounds obvious, but most teams still evaluate coding agents by asking “which model is best?” The better question is “which model is good enough for this class of task, with acceptable failure modes and cost?”
There is a governance catch. If every developer can pick the fanciest model for every task, cost visibility gets messy. If admins force cheaper models everywhere, quality drops in exactly the tasks where agent mistakes are expensive. The practical policy is a tiered matrix: cheap model for lint/test boilerplate, default model for bounded implementation, high-end model for architecture/debugging/security, and Auto only where the team is comfortable delegating routing to GitHub.
HN Algolia returned 0 matching stories for the exact GPT-5.4-mini / cloud-agent model update during the run. That silence is plausible because model multipliers are admin-console news, not launch-demo news. The real reaction will show up in usage dashboards: teams will either route simple tasks to cheaper models deliberately, or discover after the invoice that “Auto” is also a policy decision.
Route work by failure mode, not by vibes
This also matters for the Claude Code vs Codex vs Copilot comparison page. Claude Code exposes token economics more directly; Codex CLI is adding richer service-tier and usage display; Copilot is packaging model choice inside GitHub’s enterprise workflow. The winner for a given team may be the one with the cleanest controls, not the benchmark champion.
Administrators should build a task matrix before making the new models broadly available. Cheap model: lint, formatting, trivial test repairs, documentation nits. Default model: bounded implementation and routine refactors. Premium model: ambiguous debugging, architecture, migrations, security-sensitive changes, and work where a bad patch costs more than the model bill. Then measure total requests, retry rate, review correction rate, and CI survival by task class. The wrong question is which model is best. The right question is which model is good enough for this workload with acceptable failure modes.
There is also a cultural habit to break here. Engineering teams tend to treat model choice as a status hierarchy: bigger means smarter, smarter means safer, safer means default. Agent work punishes that shortcut. A smaller model with a tighter task, a clear validation signal, and a cheap retry path can be the responsible choice. A stronger model with vague instructions and no cost feedback can still turn into expensive churn.
The broader pattern is consistent across Codex, Copilot, Claude Code, and the rest of the agent stack: the interesting battleground is shifting from raw generation to operability. Can the tool be resumed, audited, priced, sandboxed, steered, and reviewed without turning every engineering team into unpaid QA for a vendor demo? That is the bar. Anything less is autocomplete wearing a hard hat.
Sources: GitHub Changelog — Copilot cloud agent: Fast, cost-efficient models for simple tasks, GitHub Docs, Copilot billing docs