LLM rankings: the leaderboard is quiet, the routers are not

The most useful AI leaderboard this week is not the one with the fanciest model name at the top. It is the one that looks suspiciously like a cloud bill.
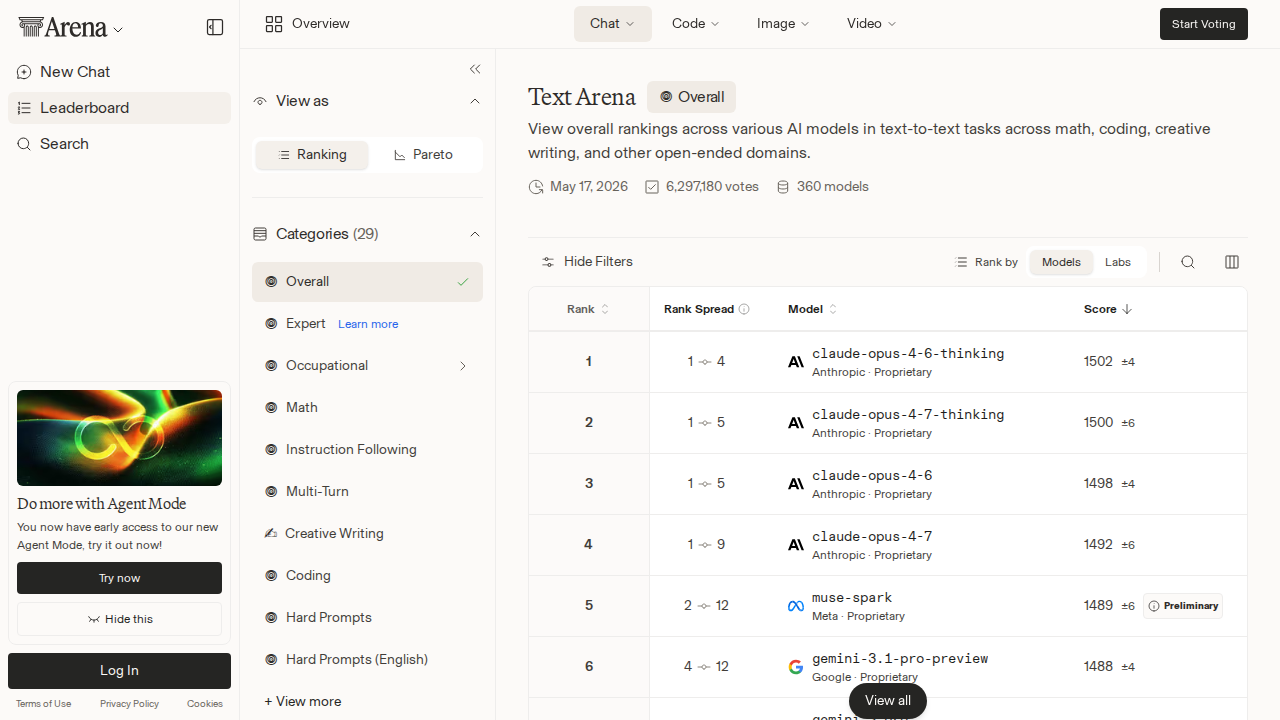
Arena Text still has Anthropic sitting comfortably in the front row: Claude Opus 4.6 Thinking at #1 with a 1502 Elo, Claude Opus 4.7 Thinking at #2 with 1500, and non-thinking Opus variants occupying #3 and #4. That is a clean story if all you care about is who wins head-to-head preference fights. But the more operational story is happening one layer down, where Qwen3.7 Max Preview just entered Arena Text at #13 with a 1475 score on 3,740 votes, and on OpenRouter the highest-volume models are not the prestige defaults. They are the cheap, fast, long-context workhorses.
OpenRouter’s weekly token board is blunt about what production teams are actually willing to call all day. Hy3 Preview is #1 with 2.68 trillion weekly tokens and 107% week-over-week growth. DeepSeek V4 Flash is #2 with 2.29 trillion weekly tokens and 92% growth. Claude Sonnet 4.6 and Claude Opus 4.7 are still strong at #3 and #4, but their growth rates — 4% and 12% — look restrained next to the surge from cheaper challengers. That does not mean Hy3 or DeepSeek suddenly became “better than Claude.” It means builders are doing the math.
The crown stayed put. The budget moved.
That distinction matters because leaderboards answer different questions. Arena asks which answer users prefer in blind comparisons. OpenRouter asks where token volume is actually flowing across routed API usage. The former is a capability signal; the latter is an economic signal.
Hy3 Preview is a good example. OpenRouter describes it as a high-efficiency mixture-of-experts model from Tencent with configurable reasoning modes, 262K context, and pricing around $0.066 per million input tokens and $0.26 per million output tokens. At those prices, teams can afford to throw it at classification, summarization, extraction, agent bookkeeping, retrieval-heavy workflows, and other jobs where “frontier-best answer” is less important than “reliable enough, fast enough, cheap enough, repeatable enough.” That is not glamorous. Neither is Postgres. Production tends to reward boring things that work.
DeepSeek V4 Flash tells the same story with a more technically interesting deployment surface. Its model card describes a 284B-parameter MoE with 13B activated parameters, a 1M-token context window, FP4/FP8 mixed precision, and MIT licensing. The model supports Non-think, Think High, and Think Max modes, and DeepSeek claims V4-Flash Max reaches 91.6 on LiveCodeBench Pass@1 and 79.0 on SWE Verified resolved. Whether those numbers survive your own harness is the point: this is now credible enough that it belongs in the eval set, not in the “interesting, maybe later” folder.
The local-control angle is especially important. Sean Goedecke’s practitioner post on DeepSeek V4 Flash and steering vectors drew real attention because it made a sharper claim than the usual benchmark victory lap: models in this class may be good enough for low-end frontier coding while exposing knobs proprietary APIs do not. That is where open-ish efficient models start becoming operationally relevant. Not because every team wants to run custom inference tomorrow, but because the option changes the negotiation. API-only frontier models are convenient; controllable models are leverage.
Qwen’s new Arena entry is a test trigger, not a migration plan
The most visible Arena movement is Alibaba’s Qwen3.7 Max Preview entering the Text top 20 at #13 with a 1475 Elo. That is high enough to notice and early enough to distrust. The vote count — 3,740 — is not nothing, but it is still preliminary compared with mature leaderboard entries. Its arrival pushed Claude Sonnet 4.6 out of the visible top 20, which is the kind of fact that will tempt people into a screenshot-driven conclusion. Resist that.
The practical read is narrower and more useful: Qwen3.7 Max Preview should go into evaluation queues for the workloads where Qwen-family models have already shown promise — multilingual tasks, code-adjacent reasoning, structured output, and price-sensitive agent loops. Qwen3.6 Max Preview is already #10 on Arena Code/WebDev, and Qwen3.6 Plus remains #15 there. That pattern says Alibaba is not merely shipping respectable general chat models; it is staying competitive in the workbench categories engineers actually test before procurement gets involved.
Still, leaderboard entry is not a deployment path. Watch whether Qwen3.7’s score holds as uncertainty narrows, whether vote count climbs, and whether the model gets accessible routing with clear pricing, latency, and context behavior. A high Arena rank plus awkward access is a curiosity. A stable score plus affordable routing is a production candidate.
Google is fighting for the base layer
Google’s movement on OpenRouter is less dramatic than DeepSeek’s raw token count, but strategically cleaner. Gemini 3.1 Pro Preview moved from #19 to #17 with 441B weekly tokens and 63% growth, while Gemini 3.1 Flash Lite Preview entered at #20 with 386B weekly tokens and 24% growth. Across the top 20, Google now has five entries if you count Gemini 3 Flash Preview, Gemini 2.5 Flash, Gemini 2.5 Flash Lite, Gemini 3.1 Pro Preview, and Gemini 3.1 Flash Lite Preview.
Flash Lite is the tell. Google positioned Gemini 3.1 Flash-Lite as the fastest and most cost-efficient Gemini 3 series model, priced at $0.25 per million input tokens and $1.50 per million output tokens. The catalog entry adds the production-friendly checklist: 1,048,576 context length, multimodal inputs, 65,536 max completion tokens, tool support, structured outputs, and reasoning controls. This is not the model you brag about on a slide. It is the model you quietly route millions of low-risk calls to because your application has more moderation, translation, extraction, UI generation, and workflow glue than deep philosophical reasoning.
The engineering move here is obvious and frequently postponed: build a real router. Classify tasks by risk, latency sensitivity, context length, required reasoning depth, output schema strictness, and blast radius if the model is wrong. Premium models should handle ambiguous, high-consequence, or high-synthesis work. Efficient models should absorb the bulk traffic: retrieval summaries, duplicate detection, preflight classification, structured extraction, lightweight code edits, test generation, and agent state maintenance. If every call in your app still goes to one premium default, that is not quality discipline. It is an unreviewed infrastructure decision.
The caution is that cheap models fail cheaply only if your system is designed to catch them. High-volume inference needs evals that measure schema compliance, tool-call precision, refusal behavior, long-context retrieval accuracy, latency distribution, and retry economics. A model that is 90% as capable at 20% of the price can be a win; a model that silently misroutes 2% of customer-impacting workflows is a support incident wearing a discount sticker.
GLM 5.1 is the non-Anthropic coding signal to keep in frame
GLM 5.1 re-entered OpenRouter’s top 20 at #19 with 391B weekly tokens and 9% growth, but its stronger claim is on Arena Code/WebDev. There it sits at #5 with a 1532 Elo, behind only Claude Opus variants and ahead of Claude Sonnet 4.6, Kimi K2.6, Muse Spark, and GPT-5.5 codex-harness variants. That is too high to wave away as random leaderboard noise.
The model’s positioning around long-horizon coding tasks is exactly where many agent systems still break. Writing one function is table stakes. Inspecting a repo, forming a plan, editing multiple files, running tests, recovering from failures, and knowing when to stop is the harder loop. If GLM’s WebDev signal survives real repository tasks, it belongs in coding-agent bakeoffs even for teams that currently think of the market as “Claude versus everything else.”
But the integration caveat is real. A technically strong model can still lose in production if provider availability, latency, documentation, safety controls, or observability are weak. Treat GLM 5.1 like a serious candidate, not a default switch: run it against actual bug fixes, UI changes, refactors, and multi-step tool workflows. Measure completion rate, review burden, test pass rate, and cost per accepted change. The leaderboard gets it into the interview. Your harness decides whether it gets hired.
The bigger takeaway from today’s rankings is that model strategy is finally looking less like brand loyalty and more like systems engineering. The best teams will not pick one winner. They will maintain an inference portfolio: premium models for judgment, cheap long-context models for volume, coding-specialized models for repo work, and open or permissive models where control matters. The leaderboard is not telling engineers to chase every new name. It is telling them to stop treating model choice as a single global constant.
That is less exciting than declaring a new king. It is also the part that will save real money and improve real products. LGTM.
Sources: OpenRouter Rankings, Arena AI Text Leaderboard, LM Arena Leaderboard, DeepSeek V4 Flash model card, Google Gemini 3.1 Flash-Lite announcement, Sean Goedecke on DeepSeek V4 Flash steering, Z.ai GLM-5.1 launch page