Privacy Middleware Is Where Agent Security Stops Being a Slide and Starts Being an API Boundary.

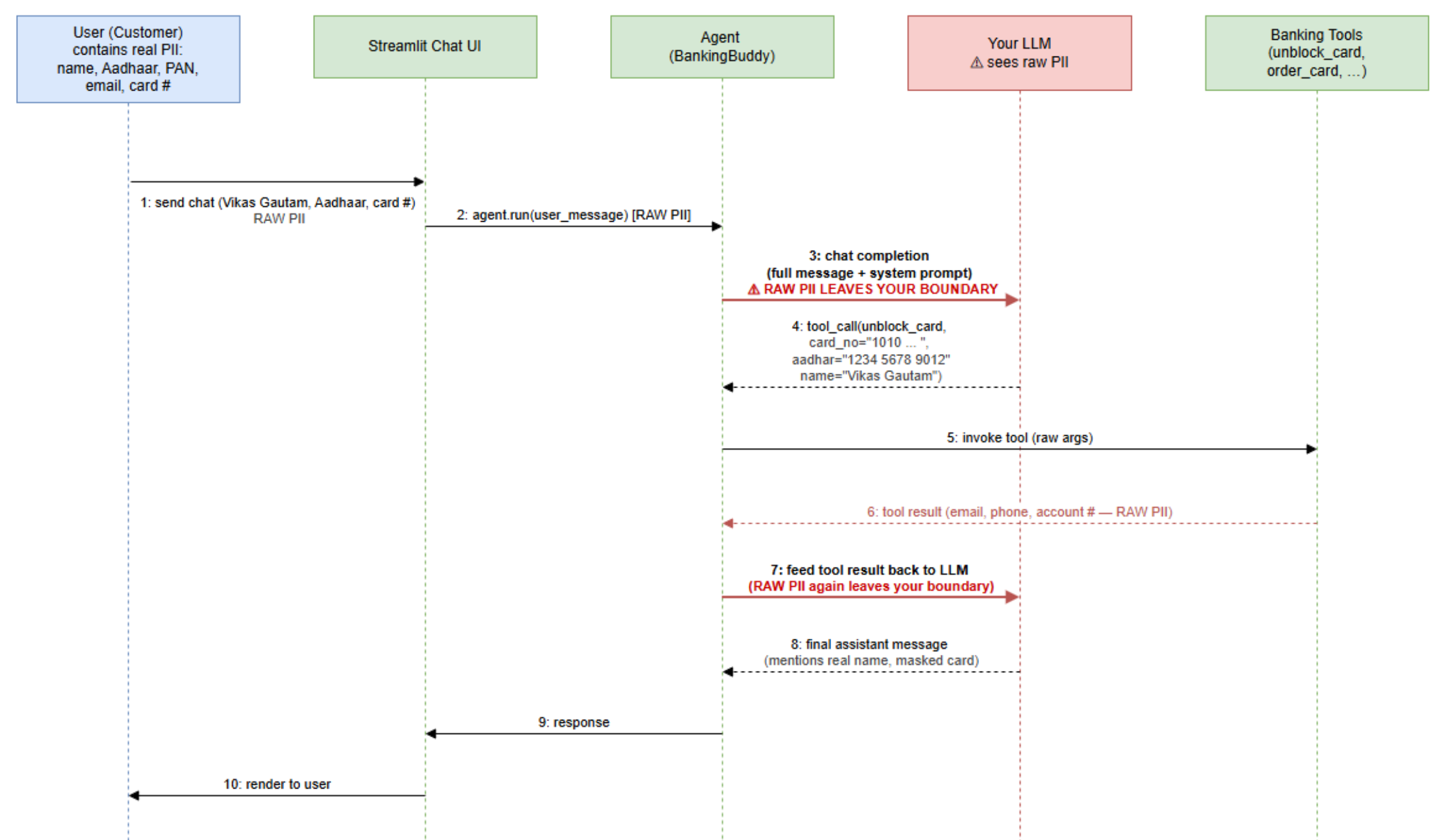
The most important part of agent security is usually not the model. It is the boundary around the model. That is why Microsoft’s privacy-proxy middleware post is more useful than its modest GitHub footprint suggests. It does not promise that an agent will become wiser, safer, or more “enterprise-ready” by vibes. It shows where sensitive data crosses the runtime boundary and how to intercept it before every prompt, tool call, and loop iteration turns into another chance to leak customer information.
The post wires PII Shield into Microsoft Agent Framework using two middleware hooks: ChatMiddleware around LLM calls and FunctionMiddleware around tool invocations. In the sample banking assistant, the model sees placeholders such as {{PERSON_1}}, {{IN_AADHAAR_1}}, and {{CREDIT_CARD_1}} instead of raw personal data. Backend tools still receive the real values when they need them. Tool results are then re-anonymized before going back into the agent loop.
That sounds like plumbing because it is plumbing. Good. Plumbing is what keeps secure systems from depending on every developer remembering the right thing under deadline pressure.
The prompt filter was never enough
A lot of LLM privacy designs still think in single-turn chat. Scrub the user prompt, call the model, maybe filter the output, and call it a day. Agents break that model immediately. They hold memory. They retrieve documents. They call tools. They pass tool results back into context. They retry. They branch. They ask other agents or services for help. Sensitive data can enter from the user, from retrieval, from tool arguments, from tool responses, from logs, from traces, and from prior turns.
That is why the paired middleware pattern matters. ChatMiddleware anonymizes outgoing messages and de-anonymizes model responses. FunctionMiddleware de-anonymizes tool arguments and re-anonymizes tool results. A shared mapping store preserves placeholders across turns and tool calls, so the model can reason consistently without seeing the raw identifiers. The model can understand that {{PERSON_1}} is the same customer throughout the conversation, while the CRM system can still receive the real customer ID it needs to do useful work.
This is stronger than a downstream output filter because it protects the model boundary before the data leaves. It is stronger than a one-time prompt sanitizer because it handles tool results that reintroduce sensitive fields later. It is also more realistic than telling every agent developer to manually call a privacy library at every possible ingress and egress point. In a real agent system, the forgotten path is the one that leaks.
Seventy milliseconds is a trade-off most teams should gladly make
The benchmark details are useful because they make the cost concrete. The post reports 1,000 paired back-to-back runs with randomized execution order against a locally deployed PII Shield service in Docker. The claimed overhead per turn: median 71.27 ms, mean 84.09 ms, 95th percentile 189.29 ms, and 99th percentile 207.44 ms.
Those numbers are not free. They are also usually not the thing users will notice in a multi-step LLM workflow. Model latency, retrieval, network hops, and tool calls already dominate most agent interactions. A predictable 100-200 ms privacy tax is very different from the unpredictable blast radius of sending account numbers, names, emails, or national identifiers into inference logs and downstream traces because one tool path skipped sanitization.
The repository context does deserve a warning label. At research time, vikasgautam18/pii-shield had 1 star and 1 fork, while the demo repo had 0 stars and 0 forks. This is fresh reference code, not battle-tested infrastructure with broad community validation. The right posture is not “install this and declare compliance.” The right posture is “this is the boundary pattern your own platform team should evaluate, harden, and adapt.”
PII Shield’s feature list is pointed in the right direction: Microsoft Presidio Analyzer and Anonymizer, entity-specific strategies such as replace, hash, encrypt, and fake, Redis-backed app configs, FastAPI endpoints, OpenTelemetry traces, metrics and logs, Azure Monitor or OTLP/Grafana support, Terraform for Azure Container Apps and Redis, and optional post-quantum encryption using ML-KEM-768 plus AES-256-GCM. But a feature list is not a threat model. Regulated teams still need adversarial testing, failure-mode analysis, tenant isolation, and hard decisions about who can reverse placeholders back into real data.
The mapping store becomes a new sensitive system
Reversible anonymization creates a sensitive asset: the mapping table. If {{CREDIT_CARD_1}} can be restored to a real card number, the store holding that relationship needs to be treated as security-critical. Encrypt it. Scope it. Expire it. Isolate it by tenant and session. Audit access. Decide what deletion means. Decide whether a support engineer can see it. Decide what happens when a workflow retries, forks, or is resumed days later.
There are also semantic edge cases. Placeholder systems can break if a model mangles tokens, if a downstream tool requires a specific format, or if the final response should show only the last four digits instead of the full restored value. Middleware can enforce a runtime boundary, but it cannot make every data-minimization decision for the product. Teams still need entity-specific policies, output templates, retention rules, and logging discipline.
That is the practical takeaway for Microsoft Agent Framework users. Middleware is the correct extension point for cross-cutting controls: privacy, logging, policy enforcement, result transformation, tool allowlists, and evaluation hooks. If every agent has to implement those separately, the organization will eventually produce one careful agent, five mostly okay agents, and one incident report. Framework-level controls are how platform teams turn security requirements into inherited behavior.
The broader Azure architecture should be layered. Agent middleware understands the semantics of messages, tool calls, placeholders, and session state. Gateways such as Azure API Management can centralize network policy, quotas, routing, and enforcement at the edge. Identity systems decide who or what can act. Audit and observability systems preserve evidence. No single layer is enough. The point of this post is that app-level middleware is one of the layers teams often skip because it is less glamorous than a model switch.
Engineers should start by inventorying every place raw sensitive data can touch an agent: user prompts, retrieved documents, memory, tool arguments, tool results, model responses, logs, traces, eval datasets, and human review queues. Then decide which values must be redacted, tokenized, encrypted, passed through, or never collected. If that policy lives only in developer memory, it will fail. If it lives at the runtime boundary, it at least has a fighting chance.
Agent security is not going to be solved by one middleware demo. But this is the shape of the solution: make privacy a default boundary, not a best-effort habit.
Sources: Microsoft Tech Community, Microsoft Agent Framework middleware docs, PII Shield on GitHub, PII agent demos