The LLM leaderboard split: Claude wins the review, DeepSeek runs the factory

The most useful LLM ranking this week is not a ranking of intelligence. It is a ranking of what developers can afford to run all day.
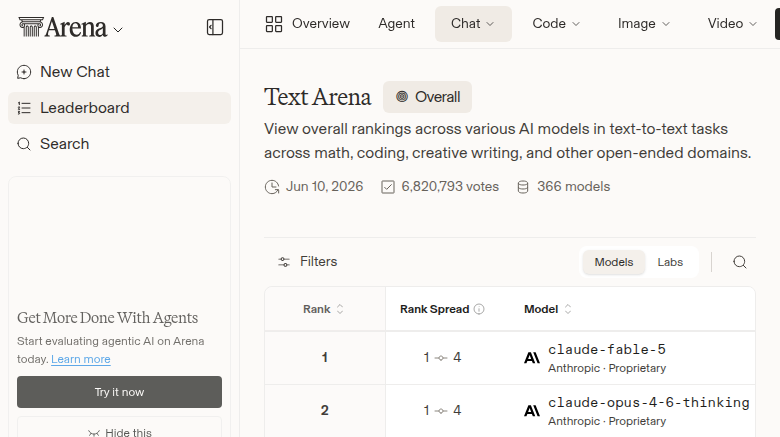
That distinction matters because the public model discourse still talks as if there is one leaderboard, one winner, and one obvious default. There is not. Arena AI says Claude Fable 5 is still the model to beat on quality, sitting at 1510 Elo on the Text leaderboard and a much louder 1665 Elo on Code/WebDev. OpenRouter usage tells a different story: the top of the token-volume chart is now DeepSeek, Tencent, MiniMax, and Xiaomi before Anthropic shows up at #5.
Both things can be true. In fact, the split is the story.
The quality crown and the factory floor are now different products
On Arena AI, the top of the leaderboard barely moved. Claude Fable 5 remains #1 on Text at 1510 Elo, followed by Claude Opus 4.6 Thinking at 1504, Claude Opus 4.7 Thinking at 1502, Claude Opus 4.6 at 1498, and Claude Opus 4.7 at 1492. On Code/WebDev, the gap is harder to ignore: Fable 5 leads at 1665 Elo, while the #2 model, Claude Opus 4.7 Thinking, sits at 1566. A 99-point spread at the top of a coding leaderboard is not “basically tied.” It is the kind of margin that should make teams pay attention before delegating a large migration or security-sensitive refactor to the cheapest endpoint in the picker.
But OpenRouter's usage ranking is not rewarding the same thing. DeepSeek V4 Flash moved to #1 with 4.5 trillion weekly tokens, up 55% week over week. Tencent's Hy3 preview is #2 with 4.1 trillion, up 52%. MiniMax M3 entered the top three with 3.63 trillion, up a ridiculous 198%. Xiaomi's MiMo-V2.5 is #4 with 3.02 trillion. Claude Sonnet 4.6, the first Anthropic model on the OpenRouter list, lands at #5 with 2.17 trillion.
If you squint, you can turn that into a regional platform story. Don't. The more useful read is operational: high-volume builders are separating “best answer” from “best unit economics.” That is what grown-up LLM adoption looks like after the demo phase ends.
Token volume is not love; it is workload shape
Weekly token volume is a dangerous metric if you treat it like an applause meter. Tokens are not votes. They are not Elo. They are not SWE-bench. They are not even necessarily revenue, depending on free tiers, caching, routing deals, and app defaults. A model can climb because it got dramatically better, because it got dramatically cheaper, because a popular agent changed its default, or because one enterprise customer started dumping long-context documents into it every night.
That is why the Hy3 signal is interesting. Max Woolf's analysis of OpenRouter usage argued that OpenRouter has unusually useful demand-side data because it sits between many applications, many users, and many model providers. His May scrape found Hy3 already beating Claude by large token volume despite sparse public discussion. He also reported a striking aggregate usage shape: roughly 98% input tokens and 2% output tokens. That is not the profile of people asking a chatbot to write poems. That is long-context agent work: ingesting histories, scanning documents, expanding retrieval, replaying tool traces, and compressing piles of state into the next step.
This is the part many benchmark debates miss. A model with a huge context window and good-enough reasoning can consume a mountain of input tokens doing unglamorous work. It can summarize logs, classify tickets, pre-read code, normalize data, extract entities, chunk documents, and maintain agent memory. None of those jobs require the smartest model in the market on every call. They require reliability, throughput, latency, price discipline, and predictable failure modes.
Meanwhile, the expensive model is increasingly the reviewer, not the intern. Claude Fable 5's Arena lead suggests it is the model you bring in when the task has ambiguity, judgment, and real downside: architecture decisions, final code review, multi-file refactors, incident analysis, regulated workflows, and anything where a plausible wrong answer costs more than the tokens you saved. Anthropic's published pricing for Fable 5 — $10 per million input tokens and $50 per million output tokens — makes that role obvious. It is cheaper than Mythos Preview, but it is still not the model you point at every background summarization job unless your cloud bill needs character development.
Gemini's drop is an economics signal, not a quality obituary
The most tempting bad take in the data is that Google's Flash stack got “worse” because Gemini 2.5 Flash Lite fell from #1 to #15 on OpenRouter, Gemini 2.5 Flash dropped from #4 to #14, and Gemini 3 Flash Preview moved from #5 to #11. That may eventually map to product pressure, but it is not a clean quality verdict. OpenRouter is showing routed usage, not controlled preference testing.
For practitioners, the drop should trigger a question, not a conclusion: what changed in routing, defaults, price, latency, context behavior, or workload mix? If your own evals show Gemini Flash is still the best cheap model for a given task, keep using it. If your app was using it only because it was the default reasonable choice six weeks ago, rerun the bake-off. The market is moving too fast for “we picked a model last quarter” to count as architecture.
The models falling out of the top 20 are just as instructive. GPT-4o-mini, GPT-OSS-120B, Mistral Nemo, Llama 3.1 8B, Qwen3 235B, and Gemma 4 31B all disappeared from this snapshot's OpenRouter top group. That does not mean they became useless overnight. It means the high-volume API market is ruthless about small deltas. If another model offers a better context-price-latency curve for a common workload, traffic moves.
The practical move: build a model portfolio, not a mascot
The engineering takeaway is boring in the way good infrastructure advice is boring: route by task. Stop asking “which model should we use?” as if your product has one kind of cognition. Ask what each call is doing, how much context it needs, what a bad answer costs, whether the output is user-visible, and whether a stronger model will verify it later.
A sensible stack now looks tiered. Use low-cost, high-throughput models for retrieval expansion, document digestion, log analysis, first-pass classification, codebase indexing, agent housekeeping, and bulk transforms. Use mid-tier models for drafts, structured extraction that needs some judgment, and interactive flows where latency matters more than perfection. Escalate to Fable 5, Opus, GPT-class high-reasoning models, or the local winner in your evals when correctness dominates cost: final patches, migration plans, security review, financial or legal analysis, and architectural calls.
Then measure the whole pipeline, not just the hero call. Track cost per completed task, retry rate, human correction rate, latency at p95, escalation frequency, and the percentage of cheap-model outputs rejected by the stronger reviewer. If your cheap model saves 70% on tokens but doubles review time, you did not optimize; you moved the bill from OpenRouter to payroll. If your expensive model improves final acceptance but spends most of its context reading boilerplate that a cheaper model could have compressed, you are burning premium reasoning on janitorial work.
Also: build observability around routing and fallback. Anthropic says Fable 5's conservative safeguards may route some sessions to Claude Opus 4.8, with those safeguards triggering in less than 5% of sessions on average. That may be perfectly reasonable. It is still something teams need to see in logs, evals, and compliance reviews. “We tested Model A but production sometimes used Model B” is the kind of footgun that only looks obvious after the incident review.
The leaderboard era is not over, but its job has changed. Arena tells you who wins the hard head-to-head. OpenRouter tells you what the market is willing to run at scale. The serious teams will read both, ignore the fan clubs, and build routing systems that treat models like infrastructure components instead of sports teams.
Claude Fable 5 looks like the current senior reviewer. DeepSeek V4 Flash, Hy3, MiniMax M3, and MiMo-V2.5 look like the factory floor. The mistake is pretending one of those roles makes the other irrelevant. The next durable AI products will not be built on a favorite model. They will be built on taste, evals, routing, and the humility to admit that “best” depends on which part of the job is on fire.
Sources: OpenRouter rankings, Arena AI leaderboard, LMArena leaderboard, Max Woolf on Hy3/OpenRouter usage, Anthropic Claude Fable 5 announcement