Gemini Live’s Hidden Model Picker Is the Interesting I/O Leak: Voice Agents Are About to Get Tiers

Gemini Live’s most interesting leak is not that Google may have a new model waiting for I/O. Of course it does. The interesting part is that Google appears to be testing a model picker for voice — which means voice assistants are about to inherit the same tradeoff menu developers already know from text models: fast, careful, personalized, experimental, and probably expensive.
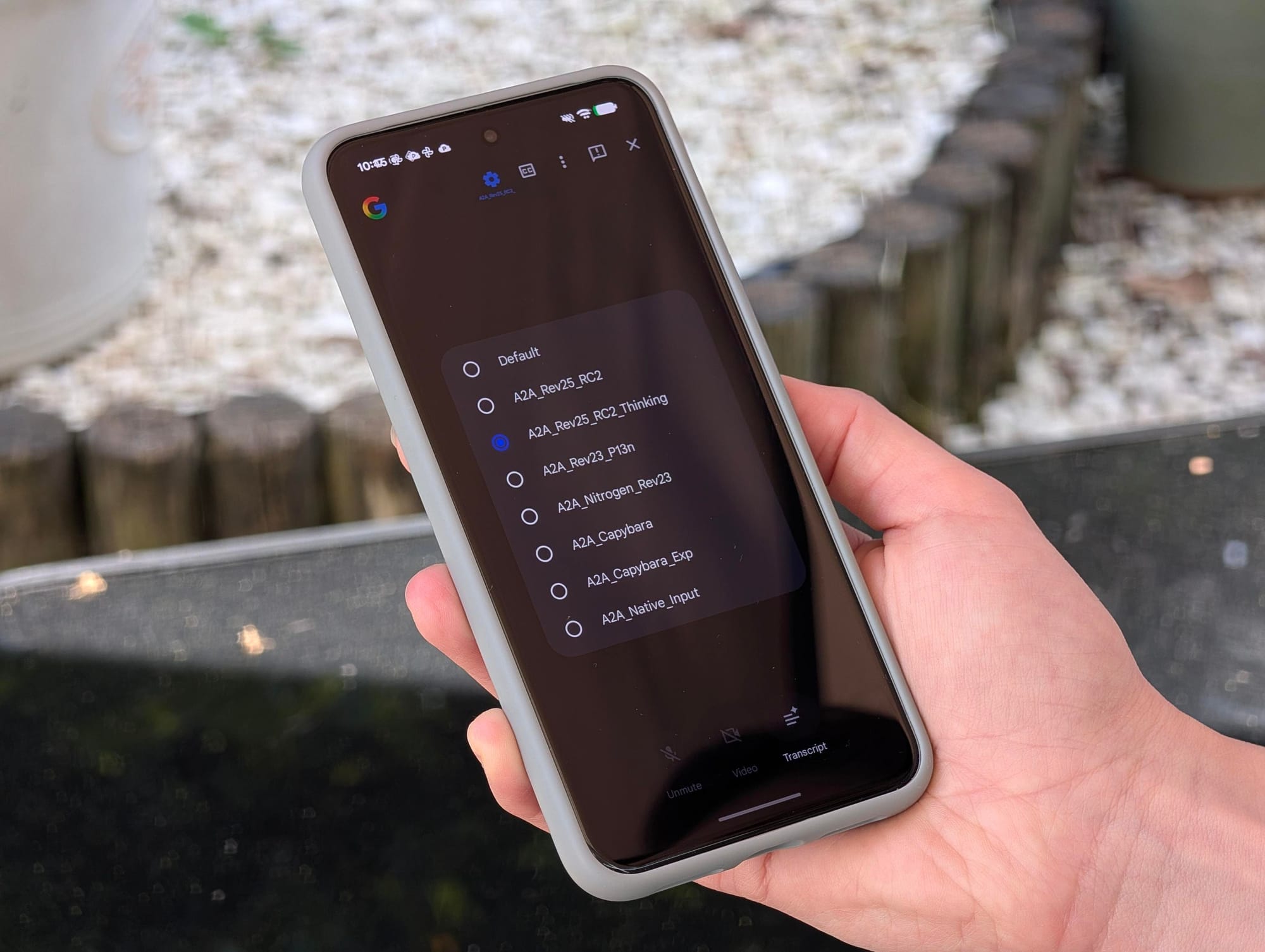
Forbes found the hidden selector while digging through Google App v17.18.22. The menu is reportedly gated by a server-side flag, which means ordinary users are not seeing it, and Google can add or remove entries without shipping another app update. The visible options include Default, A2A_Rev25_RC2, A2A_Rev25_RC2_Thinking, A2A_Rev23_P13n, A2A_Nitrogen_Rev23, A2A_Capybara, A2A_Capybara_Exp, and A2A_Native_Input. Two of those, Forbes says, appeared overnight on May 8: A2A_Rev25_RC2 and A2A_Rev25_RC2_Thinking.
Hidden flags are not product launches. They are test scaffolding until proven otherwise. But the shape of this scaffolding is hard to ignore. A2A likely means audio-to-audio, Google’s term for systems that can process speech/audio more directly instead of relying entirely on a speech-to-text model, a text model, and a text-to-speech model bolted together with hope and latency. P13n is the old personalization numeronym. Thinking is the real tell.
Voice needs a latency budget and a judgment budget
Voice assistants have spent the last decade optimizing for speed because silence is poison in a conversation. A half-second delay feels natural. A five-second delay feels like the assistant has wandered into another tab and forgotten why it opened Chrome. That bias made sense when the job was timers, weather, music, and “call the person whose name I pronounce differently every time.” It breaks down when the job becomes planning, troubleshooting, research, coaching, or tool operation.
Those tasks do not always need the fastest answer. They need the right amount of thinking. A user asking “what’s on my calendar?” wants speed. A user asking “help me reschedule this trip without breaking the budget, missing the school pickup, or booking a garbage layover” wants the assistant to slow down, inspect constraints, call tools, and maybe ask a clarifying question before touching anything. One default voice model is the wrong abstraction for both jobs.
That is why a hidden Thinking tier matters more than a model codename. Google already trains users to expect tiered text experiences: cheaper/fast models, more capable reasoning models, and premium modes with better context or tools. Gemini Live has not exposed that kind of choice in the same way. If Google turns this into a public product surface, the consumer label will not be A2A_Rev25_RC2_Thinking. It will be something more legible: “fast answer,” “careful answer,” maybe “personal assistant.” Under the hood, though, it is model routing.
That routing is where builders should pay attention. Google’s public Gemini Live story is already more than a voice chat toy. Gemini 3.1 Flash Live, launched through the Live API in March, was positioned for low-latency voice and vision agents with improved instruction following, natural dialogue, noisy-environment reliability, and support for more than 90 languages. The Live API docs point to the primitives developers actually need: multilingual sessions, tool use, function calling, session management for long-running conversations, and ephemeral tokens.
Add model-tier selection to that stack and Gemini Live starts to look less like an assistant feature and more like a runtime for real-time agents. A sane voice-agent architecture will route easy turns to a low-latency audio model, escalate complex turns to a reasoning-capable model, preserve session state, call tools only when needed, and return to normal conversation without asking the user to manage the pipeline. Users should not have to know which model is active. Developers absolutely should.
Personalization is the feature and the liability
The personalization hint is both useful and uncomfortable. A personalized voice model could make Gemini Live dramatically better: fewer repeated preferences, better defaults, more accurate task routing, and less “as an AI language model” furniture in the conversation. If an assistant knows how you travel, which calendar conflicts are real, which contacts matter, which restaurants you hate, and what “the usual report” means, it stops feeling like a chatbot and starts feeling like software with memory.
It also moves the trust boundary from “AI feature” to “ambient system.” Personalized voice agents sit close to the user’s life: calendar, inbox, contacts, location, device state, maybe screen or camera context. If Google shows this direction at I/O, the hard questions are not just latency and naturalness. They are context questions. What is used? Where is it processed? How long is it retained? Can developers request personalization selectively? Can enterprises disable it? What does consent look like when a live voice session blends user memory with tool calls?
These are not policy footnotes. They are product constraints. A voice agent that can personalize but cannot explain what it knows will lose trust quickly. A voice agent that can call tools but cannot make authority boundaries obvious will be a prompt-injection incident waiting for a conference talk. The right implementation is not “let the model decide.” It is explicit task classes, confirmation gates, scoped tokens, visible logs, and boring controls users can actually find.
The competitive pressure is obvious. OpenAI and Anthropic have made agentic workflows feel concrete in coding, computer use, and async task execution. Google’s advantage is not a single chat window; it is distribution across Android, Chrome, Workspace, Search, YouTube, the Gemini app, AI Studio, Vertex, and eventually XR. Voice is the interface that can stitch those surfaces together. If Gemini Live gets reasoning tiers and personalization, Google can make agents feel less like a destination and more like a system layer.
That does not mean this exact selector ships. Server-side menus routinely expose experiments that die quietly. RC2 sounds closer to release-candidate territory than random lab sludge, but leaked labels are not launch commitments. The useful read is platform pressure: real-time AI products are outgrowing the one-model voice assistant. Google needs a voice stack that can be fast, deliberate, personal, multimodal, and tool-aware without collapsing into UX spaghetti.
Practitioners should treat this as a design prompt. If you are building with voice agents, stop designing single-model demos. Categorize your tasks by latency tolerance, error cost, privacy sensitivity, and tool authority. Decide which actions can be answered immediately, which require reasoning, which require confirmation, and which should never happen over voice. Build observability around model routing and tool calls. The teams that understand these tradeoffs before Google exposes them in a glossy I/O slide will move faster when the APIs catch up.
The take: Gemini Live’s hidden picker is not interesting because of Capybara, though credit where due, that codename clears review. It is interesting because voice agents are becoming tiered infrastructure. The next useful assistant will not always answer fastest. It will know when to be quick, when to think, when to personalize, and when to stop before touching the user’s life.
Sources: Forbes, Google Gemini 3.1 Flash Live announcement, Gemini Live API docs, Google I/O 2026, PCWorld