Hermes on DGX Spark Shows Local Agents Are Becoming a Hardware Product — With a Reliability Bill Attached

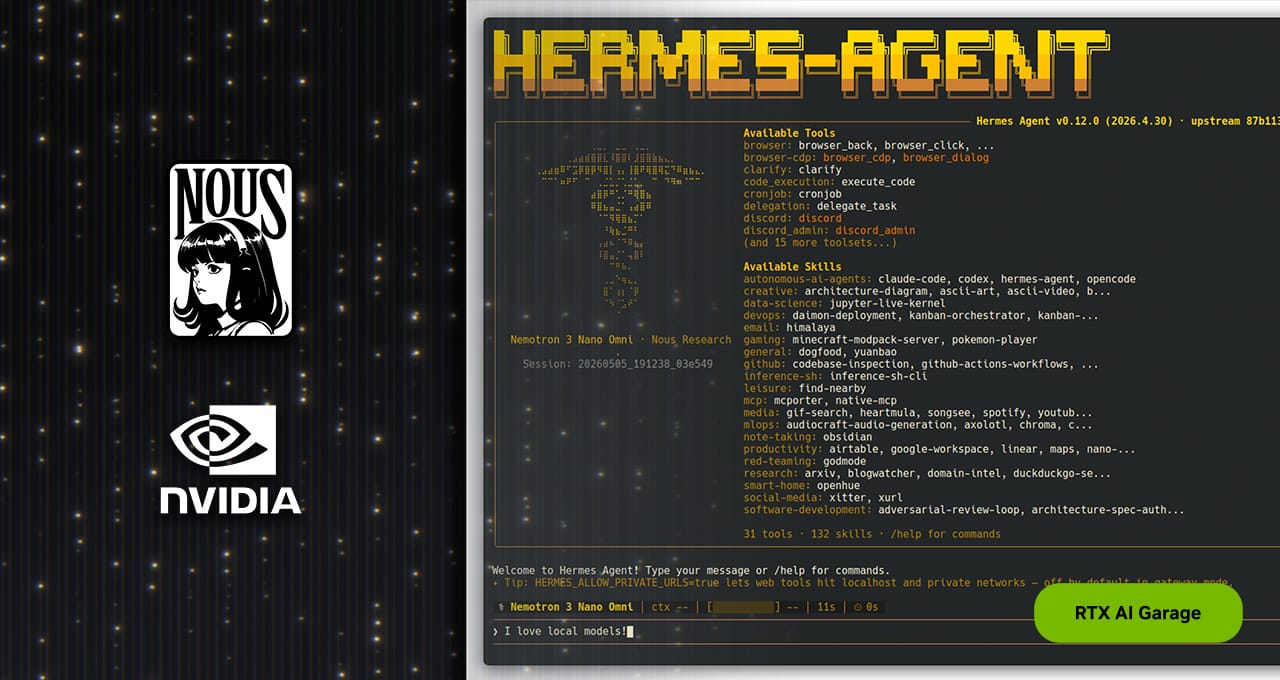
NVIDIA’s latest RTX AI Garage post is not really about one more agent framework. It is about local agents becoming a hardware product. Hermes Agent, Qwen 3.6, RTX PCs, RTX PRO workstations, and DGX Spark are being bundled into a single story: keep the agent near your files, memory, tools, and workflows, then give it enough local compute to stay alive all day.
That is a more serious pitch than “run AI on your PC.” Local inference used to be framed mostly as a privacy feature or a hobbyist flex. NVIDIA is now selling the full operating shape: provider-agnostic agent harness, persistent memory, contained subagents, self-evolving skills, local model serving, and enough GPU memory to make the loop feel less like a science project.
The company says Hermes crossed 140,000 GitHub stars in under three months and was, as of last week, the most-used agent on OpenRouter. Treat the OpenRouter claim as NVIDIA’s cited claim rather than an independently verified scrape; the rendered rankings page is not especially friendly to external extraction. The GitHub-side substance is easier to inspect. Hermes documents multi-channel gateways, provider abstraction, terminal backends, OpenClaw migration, skills, memory, MCP integration, cron, and security docs. In other words: it is trying to be an always-on personal/engineering agent, not a single chat UI with tool calls bolted on.
The local-agent stack is becoming legible
The model side is where NVIDIA’s argument gets concrete. NVIDIA says Qwen 3.6 35B runs in roughly 20GB of memory while surpassing 120B-parameter models that require 70GB or more. It also says Qwen 3.6 27B is a dense model that matches the accuracy of 400B-class models such as Qwen 3.5 397B while being one-sixteenth the size. Those are vendor-framed benchmark claims, so do not turn them into theology. But they point at the real operator question: what model is good enough to stay resident, respond quickly, and survive long tool loops?
Ollama’s Qwen3.6 page listed 1.2 million pulls during research, which is the stronger adoption signal. People are actually trying these models locally. The page also highlights agentic coding and “thinking preservation,” a feature aimed at retaining reasoning context from historical messages. That matters because local agents are less about one perfect answer and more about durable state: what happened in the last session, what the user prefers, which repo conventions matter, which tool chain fails in predictable ways.
DGX Spark is the high-end version of the same narrative. NVIDIA calls out 128GB of unified memory and 1 petaflop of AI performance, and says the system can run 120B-parameter mixture-of-experts models all day. RTX PRO GPUs get their own throughput pitch, with NVIDIA claiming up to 3x faster token generation for Qwen 3.6 under llama.cpp and up to 3x faster inference for Gemma 4 NVFP4 checkpoints with Multi-Token Prediction drafters on Blackwell GPUs.
The important shift is that NVIDIA is no longer just saying GPUs accelerate AI. It is describing a local-agent appliance category: model, runtime, memory footprint, persistence, serving engine, and agent harness. That is exactly how this market becomes practical. Developers do not buy “AI.” They buy a box or workstation that can run their repo assistant, personal operations daemon, test fixer, inbox triager, or private coding worker without leaking everything into a cloud session.
Always-on agents also carry an always-on reliability bill
Hermes’ most interesting features are not the ones that sound magical. Persistent memory, skill creation, self-improvement, session search with LLM summarization, cross-session user modeling, contained subagents, scheduled work, and multi-channel access are the features that make a local agent useful. They are also the features that make it dangerous if treated casually.
A system that writes its own skills, remembers user context, spawns workers, reads messages, calls tools, and runs across Slack, Telegram, Discord, WhatsApp, Signal, CLI, and email is no longer just a model endpoint. It is a long-lived software system with authority. Local does not automatically mean safe. It only means the blast radius is closer to your files, your credentials, and your automation.
That is why NVIDIA’s adjacent OpenShell push matters. If Hermes is the “agent that does things,” OpenShell is the admission that agents need external containment. Builders should connect those stories immediately. A useful local agent needs scoped filesystem access, network policy, approval gates, rollback for learned skills, tool allowlists, credential boundaries, and logs that survive the agent’s own narrative about what it did.
The right evaluation method is boring and brutal. Put Hermes/Qwen on real repository tasks. Measure p95 latency under long context, not just tokens per second on a clean prompt. Force allowed-file constraints and inspect diffs directly. Track whether learned skills improve repeated work or encode brittle assumptions. Run separate implement/review/fix loops. Treat model summaries as claims, not evidence. If the agent says it only touched two files, verify the git diff outside the model.
This is where local agents can beat cloud chat even when the frontier model is smarter. A merely good local model that is private, cheap to run, always available, stateful, and wired into your environment can become more useful than a stronger model trapped behind a stateless request/response interface. But that only works if the surrounding harness turns the model into a constrained worker rather than an autonomous authority.
The LGTM take: NVIDIA is right that local agents are becoming a product stack. Qwen-class models make the workload plausible, Hermes supplies the persistent orchestration, and DGX Spark/RTX supplies the always-on compute. The catch is not whether the demo works. The catch is whether teams pay the reliability bill in policies, tests, sandboxes, and logs before the agent becomes a very confident daemon with write access.
Sources: NVIDIA Blog, NousResearch Hermes Agent GitHub, Ollama Qwen3.6, OpenRouter apps, NVIDIA OpenShell context