NVIDIA Wants Chemistry AI to Look More Like a GPU Data Pipeline Than a Lab Notebook

Scientific software has a bad habit of accelerating the glamorous 20% and leaving the messy 80% untouched. A model gets faster, a kernel gets smarter, a benchmark chart gets prettier, and then the actual workflow still spends half its time shuttling data through CPU-heavy glue code written for an earlier era. NVIDIA’s new ALCHEMI Toolkit matters because it targets that glue layer in computational chemistry and materials science, which is usually where promising research pipelines go to die at scale.
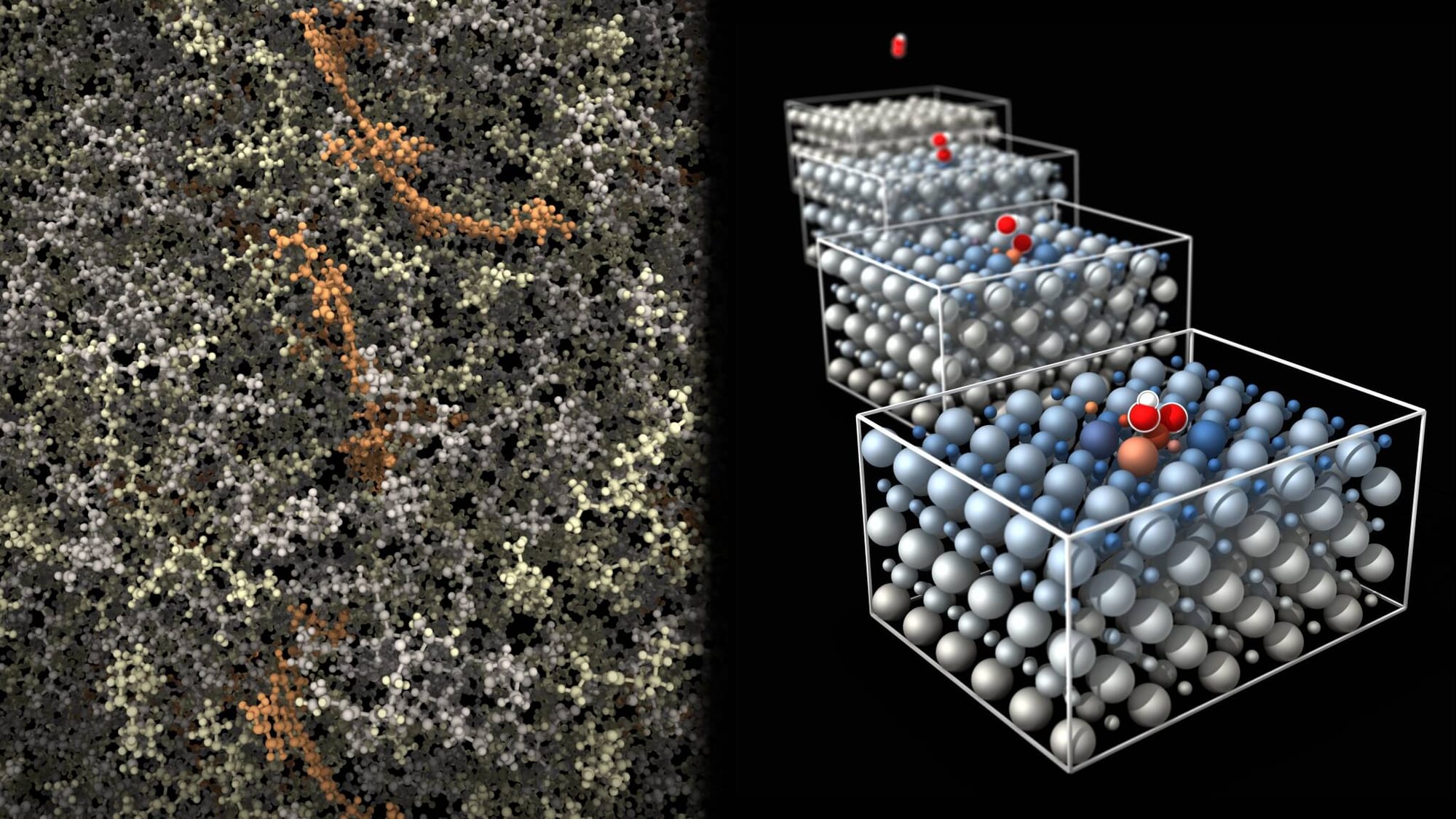
The company is positioning ALCHEMI Toolkit as the next step in its AI-for-chemistry stack, sitting above Toolkit-Ops and alongside ALCHEMI NIM microservices. The headline is not a single model. It is a PyTorch-native framework for building batched atomistic simulation workflows on GPUs, with support for geometry relaxation, molecular dynamics, data structures, distributed pipelines, and wrappers for common ML interatomic potential models such as MACE, TensorNet, and AIMNet2. NVIDIA says early ecosystem integrations already show why the orchestration layer matters: Orbital reports roughly 1.7x acceleration on large systems and about 33x on batched smaller systems using Toolkit-Ops-backed graph construction, while Matlantis reports up to 10x speedups on selected atomistic operations.
That sounds niche until you zoom out. Chemistry and materials discovery is increasingly an AI systems problem, not just a model-quality problem. Researchers want near-quantum accuracy without DFT-level pain. They want to evaluate millions of molecular configurations, not dozens. They want simulation pipelines that can combine learned potentials with physics-based corrections, keep data on device, batch aggressively, and scale across multiple GPUs without turning each experiment into a custom distributed systems project. That is the gap ALCHEMI Toolkit is trying to close.
The part I find most credible is the emphasis on dataflow. NVIDIA is explicitly describing ALCHEMI as a way to manage movement between scientific kernels and deep learning models while keeping the entire workflow GPU-resident. That sounds mundane, but in practice it is where throughput disappears. Scientific teams often adopt a GPU-accelerated model and then feed it through host-side preprocessing, Python orchestration overhead, fragile file interfaces, and CPU-bound batching logic. The result is an expensive accelerator waiting on software decisions made for a much smaller scale.
ALCHEMI’s architecture is an attempt to modernize that middle layer. The toolkit includes batched dynamics engines, composable workflows, hooks for custom optimization and annealing logic, support for common scientific formats through ASE and Pymatgen-style interfaces, and distributed execution patterns that can pipe one stage of a simulation to another across multiple ranks and GPUs. NVIDIA’s examples are telling. This is not “here is a cool model, good luck.” It is “here is the machinery for chaining geometry optimization into molecular dynamics, fusing stages on one GPU or splitting them across many, while keeping the batching and data movement efficient.”
That is a very NVIDIA move. The company keeps finding vertical workloads where the real bottleneck is no longer the core math primitive but the stack wrapped around it. Then it absorbs that wrapper into the platform. In AI training, that meant optimized communication libraries, inference runtimes, and deployment frameworks. In robotics, it meant simulation and edge orchestration. In chemistry, it now means taking the awkward glue between MLIPs and production-scale simulation and making it GPU-native.
There are two strategic implications here. First, NVIDIA is making a strong bid to define the default substrate for industrial scientific computing in the same way it defined large parts of mainstream AI infrastructure. If your chemistry workflow depends on ALCHEMI Toolkit, Toolkit-Ops, NIM services, PyTorch integration, and CUDA-tuned kernels, the path of least resistance runs deeper into the NVIDIA stack. Second, the company is betting that scientific users increasingly care about workflow programmability as much as raw model accuracy. That is the right read of the market. The winning platform is usually the one that turns expert-only pipelines into something a broader engineering team can actually maintain.
Practitioners should read this less as a press release for chemists and more as a case study in where GPU computing is going. Domain-specific AI is maturing past “model zoo” thinking. What matters now is whether the surrounding system can express real workflows, integrate existing tools, scale cleanly, and keep utilization high. ALCHEMI’s support for custom dynamics classes, composable calculators, and advanced data management is a direct answer to that problem.
There is also a cultural point buried here. Scientific software has historically tolerated rough edges because the users were specialists willing to fight through them. That assumption breaks once the target is industrial deployment, high-throughput screening, or startup-scale productization. Teams do not just need accuracy. They need maintainable APIs, reproducible runs, packaging that works, and a sane way to move from a research notebook to a multi-GPU service. ALCHEMI is NVIDIA betting that chemistry and materials teams are now at that transition point.
The operational advice is straightforward. If you work in atomistic simulation, evaluate the toolkit on workflow shape, not just isolated speedups. Ask whether it reduces CPU-GPU transfer overhead in your real pipeline. Test whether its batching model actually improves throughput on your target molecule sizes. Check how easily your existing MLIPs can be wrapped, and whether the distributed pipeline abstractions match the way your team runs jobs today. And if you are building a scientific software product, pay close attention to the composability story. The long-term value here is not one benchmark claim. It is whether ALCHEMI lets you ship a virtual lab that behaves more like an engineered system and less like a fragile research artifact.
My take is simple. NVIDIA wants chemistry AI to look less like a sequence of bespoke scripts and more like a GPU data pipeline. That is a good instinct, because the next bottleneck in scientific discovery is not generating more models. It is turning them into repeatable, scalable workflows that people outside a single research group can operate. If ALCHEMI succeeds, the chemistry story will look a lot like the rest of NVIDIA’s business: win the orchestration layer, and the hardware sale becomes the easy part.
Sources: NVIDIA Technical Blog, NVIDIA ALCHEMI