Copilot Code Review With MCP and Medium Effort Makes Review Automation a Budgeted Platform Feature

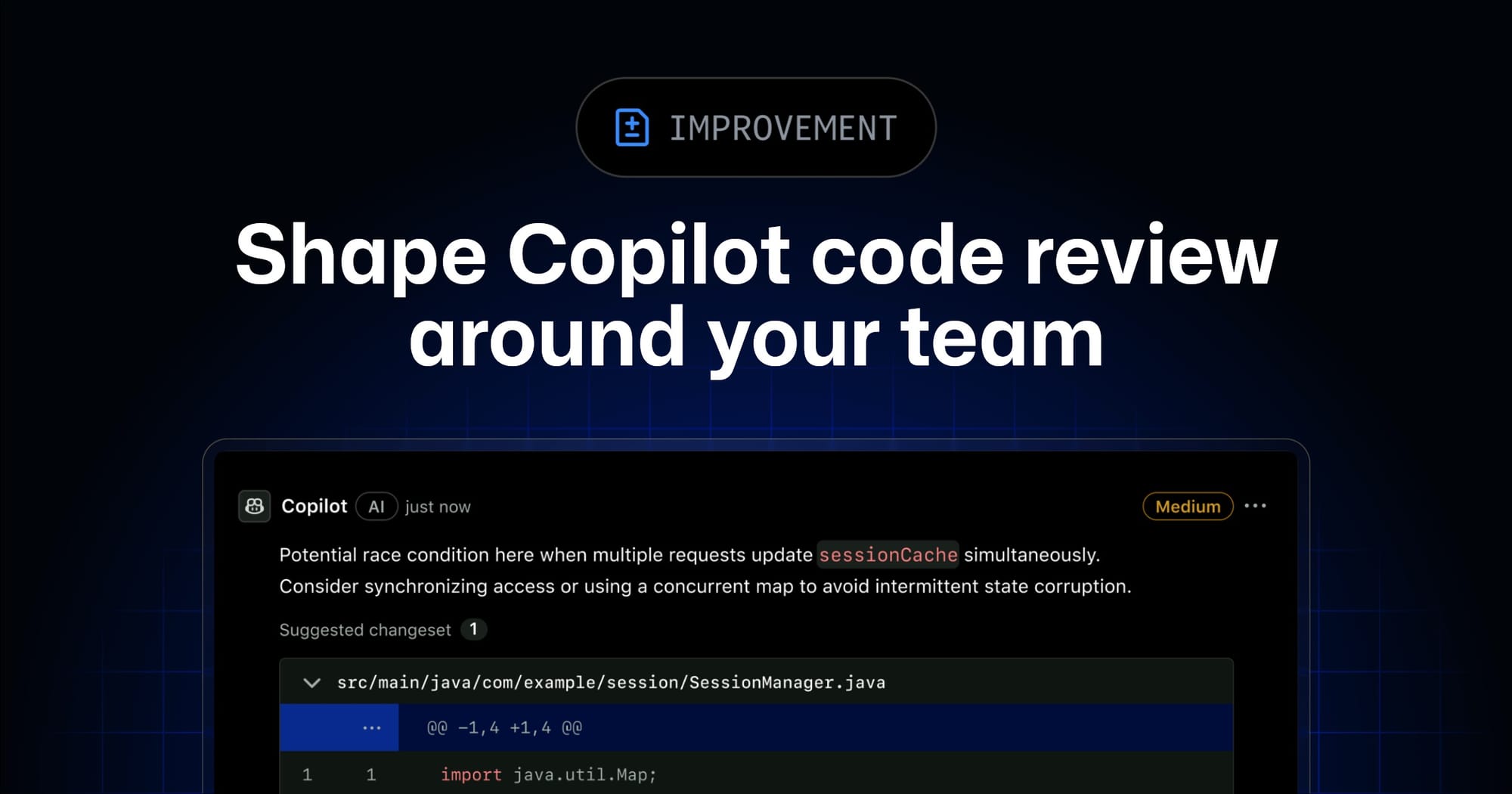
Copilot code review is no longer just a bot commenting on pull requests. GitHub’s latest previews turn it into a budgeted platform feature: connected to MCP context, shaped by repository skills, routed through configurable reasoning effort, and billed through AI credits and sometimes Actions minutes. That is the correct direction. It is also where teams need to stop treating “AI review” as free background magic.
GitHub shipped two public previews under the banner of shaping Copilot code review around your team. First, code review can use custom agent skills and MCP servers to bring team context into the review. Second, teams can choose a Medium analysis tier for more complex PRs, while Low remains the faster default. The docs make the operational implications explicit: Copilot code review spans GitHub.com, GitHub CLI, GitHub Mobile, VS Code, Visual Studio, Xcode, JetBrains, and Azure DevOps public preview; agentic review can use GitHub Actions runners for fuller project context and cloud-agent fix PRs; Medium consumes more AI credits than Low and may use more Actions minutes.
That combination changes the product category. A reviewer that reads team policy, queries internal tools, runs on compute, opens fixes, and consumes credits is not a nice-to-have assistant. It is CI with opinions.
MCP makes reviews useful by making them dangerous
Review without context is shallow. A diff alone does not know that the touched service had an incident last week, that the endpoint is owned by another team, that a feature flag must wrap migrations, that the customer tier matters, or that the authentication path has a special compliance rule. Human reviewers carry that context from docs, memory, incident history, service catalogs, and painful scars. A language model reviewing only the patch will miss much of it.
MCP is GitHub’s answer to that gap. Code review can connect to MCP servers that pull context from issue trackers, documentation, service catalogs, incident tooling, and internal or third-party systems. Existing MCP configurations for the Copilot cloud agent apply automatically to Copilot code review. Agent skills live under .github/skills, with a code-review or similarly named directory recommended for review-specific instructions.
That is genuinely useful. It is also a new supply chain. The review model is now influenced not just by code and prompt, but by tool descriptions, skill files, MCP responses, stale docs, service metadata, and whatever permissions those integrations expose. A poisoned service-catalog entry can become review guidance. A vague SKILL.md can institutionalize weak standards. A stale incident link can convince the reviewer to optimize for yesterday’s problem.
The right response is not to avoid MCP. The right response is to govern it like code. Keep review skills short, specific, and versioned. State actual policy: security boundaries, migration rules, ownership expectations, test requirements, logging standards, and known anti-patterns. Connect only MCP sources with clear owners and audit trails. If the docs are not trusted enough for a human reviewer, they are not trusted enough for a model reviewer. “It gives the agent more context” is not a security review.
Medium effort should be routed, not sprayed
The Medium analysis tier is designed for complex logic, security-sensitive code, and cross-service changes. Admins can set Low or Medium per repository through repository settings under Copilot code review. That is a sensible first control, but it is too coarse to be the final shape. Mature teams will eventually want routing by path, label, branch, CODEOWNERS, PR size, dependency type, and risk classification.
Not every pull request deserves a premium reasoning model. Documentation edits, small UI copy, generated files, fixture updates, routine test changes, and straightforward dependency bumps usually need speed and consistency, not deep analysis. Cross-service auth changes, payment logic, migrations, permissions, concurrency primitives, crypto, infrastructure-as-code, and incident-related fixes absolutely deserve a more expensive look. Treating all PRs the same is lazy in both directions: Low everywhere misses subtle risk; Medium everywhere burns money and reviewer attention.
This is the same lesson engineering already learned from CI. You do not run the full end-to-end suite on every Markdown change unless you enjoy waiting and paying. You route checks based on affected paths, risk, and confidence. AI review needs the same routing discipline. Start with repository-level defaults if that is the control GitHub gives you today, then use manual escalation for high-risk PRs until finer-grained policy exists.
The pricing details matter because they will shape behavior. GitHub says Medium consumes more AI credits than Low. Docs add that Medium can use more GitHub Actions minutes and may benefit from larger or self-hosted runners. Code review for users without a Copilot license can be enabled for Copilot Business and Enterprise organizations, but it requires AI credits paid usage and is disabled by default. Automatic code review charges credits to the PR author; manually requested reviews charge the requester; bot-created PRs bill the triggering user when identifiable or a designated billing owner.
Those rules turn review automation into a spend allocation system. If a bot opens 200 PRs and auto-review runs Medium on all of them, that is not an AI experiment. That is a budget event.
Measure useful comments, not bot activity
The public reaction around Copilot billing is already noisy. Research surfaced a Hacker News thread with users describing quota burn from agentic workflows, including one report of using more than half a monthly quota in a day and another of losing 30% of included credits while intentionally trying to use less. Reddit snippets around Copilot credits are similarly unhappy. Some of that is normal pricing-change grumbling. Some of it is a real warning: agentic workflows can burn credits quickly when teams do not understand the unit economics.
For review automation, the metric cannot be “number of AI comments posted.” That metric rewards noise. The useful metrics are harsher: percentage of comments accepted or acted on, false-positive rate, fix acceptance rate, time-to-merge impact, defects caught before merge, escaped defects after merge, cost per PR, cost per accepted fix, and human reviewer satisfaction. If Medium catches real bugs in security-critical repositories, pay for it. If it produces expensive style nits and speculative warnings, turn it down or rewrite the skill.
There is also a cultural risk. Teams already struggle with low-signal review bots. Linters that comment on formatting instead of enforcing it become background noise. Security scanners with too many false positives get ignored. An AI reviewer with access to MCP context and higher reasoning can be better than that, but only if its output is treated as a product surface. Tune it. Prune it. Give it policy. Remove instructions that generate generic advice. Make the reviewer cite the rule, context source, or test evidence behind important claims.
The rollout should be boring
A good setup starts small. Create a minimal .github/skills/code-review/SKILL.md that states the team’s actual review policy. Do not write “be thorough” and call it a day. Say what must block merge: missing tests for changed behavior, unsafe migrations, unreviewed auth changes, logging of secrets, production config edits, breaking API changes, or missing rollback notes. Include repo-specific architectural constraints where they are real. Keep the file short enough that humans will review it in PRs.
Then connect MCP cautiously. A service catalog can help the reviewer identify owners and blast radius. An issue tracker can connect a PR to requirements. Incident tooling can surface related outages. Internal docs can explain migration policy. But each source needs an owner, freshness expectations, and a way to audit what the reviewer saw. If an MCP server can expose sensitive data irrelevant to code review, scope it down before connecting it.
Finally, set effort levels deliberately. Use Low for routine repos or routine change classes. Use Medium for security-sensitive, high-blast-radius, or complex systems. Wire billing alerts before enabling automatic review for everything. If non-licensed users are enabled through Direct Org Billing, document who owns the spend. If runner usage grows, decide whether larger or self-hosted runners are justified by better review quality.
The editorial take is simple: Copilot code review is growing up into platform engineering. MCP context and Medium reasoning can make reviews meaningfully better, but only if teams treat them like paid, policy-bearing CI. Otherwise they will get the worst version of automation: a confident bot, a rising bill, and a review queue full of comments everyone learns to ignore.
Sources: GitHub Changelog, GitHub Docs, GitHub Community discussion #197304, GitHub Copilot plans and pricing