LLM rankings are splitting into quality and economics

The model leaderboard story this week is not that Anthropic still looks excellent on Arena. It is that the two most useful public scoreboards are now measuring different planets: Arena is still a quality contest, while OpenRouter has quietly become a production-economics chart.
That distinction matters because teams keep treating model rankings like dependency version numbers: bigger rank, better choice, upgrade immediately. The current data argues for the opposite. If you are building with LLMs in production, the question is no longer “which model is best?” It is “which model is good enough at the point where latency, cache behavior, routing availability, and retry rates stop eating the product?”
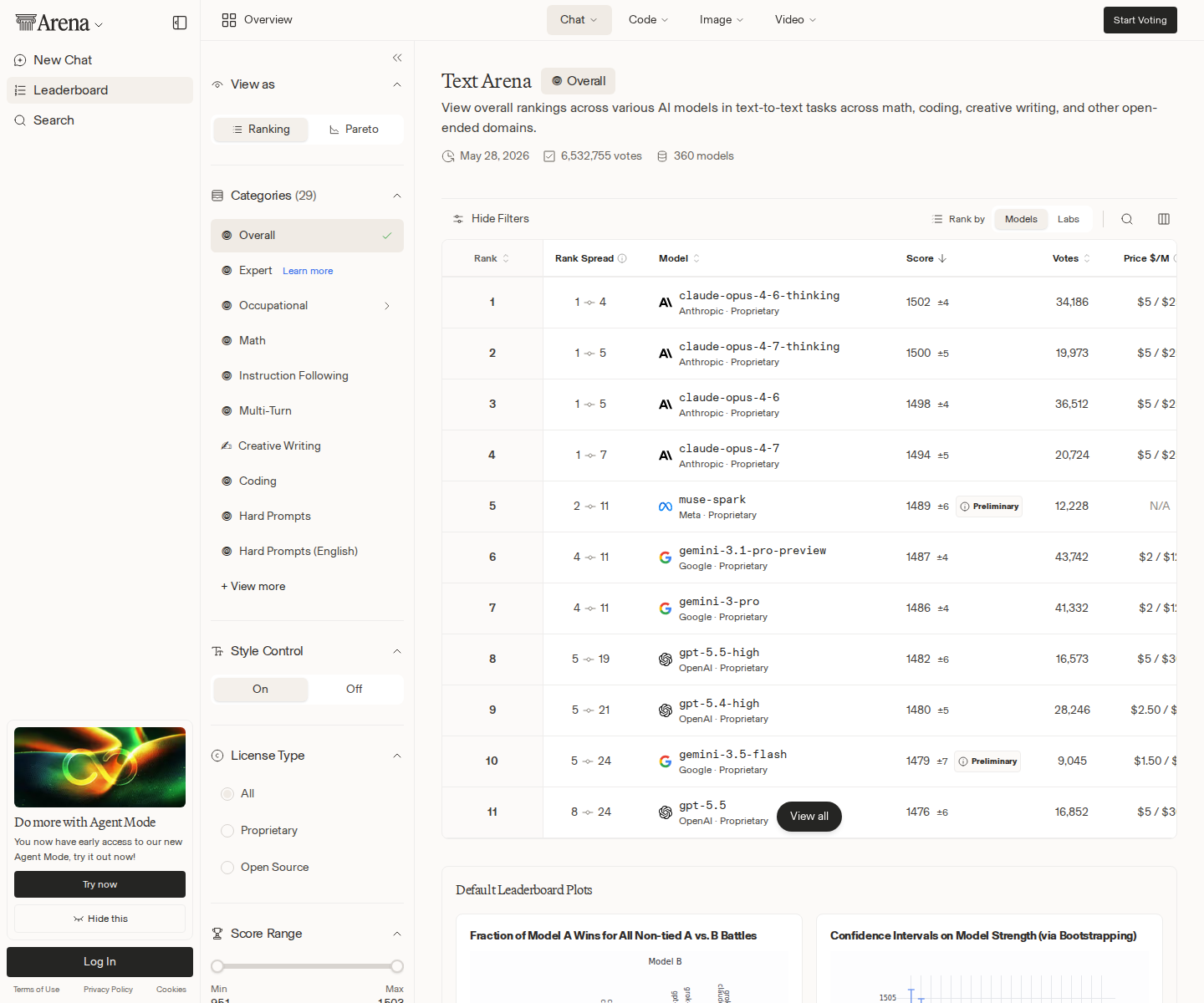
Arena AI’s Text leaderboard was basically frozen in the latest scrape. The same 20 models held the same ranks day over day. Anthropic owns the top four slots: claude-opus-4-6-thinking at 1502 Elo, claude-opus-4-7-thinking at 1500, claude-opus-4-6 at 1498, and claude-opus-4-7 at 1494. Meta’s muse-spark follows at 1489, with Google’s Gemini 3-family models, OpenAI’s GPT-5.x entries, xAI’s Grok 4.20 variants, Alibaba’s Qwen, and Z.ai’s GLM packed close behind.
That is a strong showing for Anthropic, but the more important number is the spread. Arena’s top ten runs from 1502 Elo to 1479 Elo — a 23-point band before you even start caring about confidence intervals. The vote counts also vary widely: Claude Opus 4.6 has more than 36,000 votes in one non-thinking variant and more than 34,000 in the thinking variant, while newer or more speculative entries like qwen3.7-max-preview have far less public signal. This is not a clean cliff from “great” to “bad.” It is a top cohort, and treating rank #1 as automatically deployable is the kind of benchmark cargo culting that gives postmortems their plot.
Usage is voting with a smaller wallet
OpenRouter’s rankings tell a very different story. The top three remained stable — Google Gemini 2.5 Flash Lite at 29,388,441 weekly requests, DeepSeek V4 Flash at 28,285,845, and OpenAI GPT-4o-mini at 20,261,740 — but the middle of the chart moved enough to be interesting. Gemini 2.5 Flash climbed from #5 to #4, nudging Gemini 3 Flash Preview down. DeepSeek V3.2 moved from #7 to #6, while OpenAI’s gpt-oss-120b slipped to #7.
The new entry worth watching is inclusionAI’s Ling-2.6-flash, which landed at #9 with 10,220,316 weekly requests. That puts it ahead of Gemini 3.1 Flash Lite, Claude Sonnet 4.6, Mistral Nemo, Meta’s Llama 3.1 8B Instruct, and several other names with more mindshare in Western developer circles. Models do not usually appear in the top 10 of a usage marketplace because a few people liked a demo. They get there because some combination of price, speed, provider availability, app defaults, free-period incentives, or workload fit is pushing real traffic through them.
Meanwhile, Claude Opus 4.7 fell from #11 to #17 despite still handling 6,533,194 requests. That is the useful nuance: expensive frontier models are not irrelevant. They are just not where bulk volume necessarily concentrates. A model can be the right choice for hard reasoning, code review, long-horizon agent planning, or high-value tasks and still lose the request-count race to cheaper fast models doing classification, extraction, chat, autocomplete, routing, and “good enough” assistant work all day.
This is why OpenRouter’s chart is increasingly an economics benchmark disguised as a popularity leaderboard. It exposes not just preference but behavior: what developers and apps actually route through an intermediary when cost and latency are part of the decision. The leaderboard also includes practical serving signals like request count, p50 latency, p50 throughput, and provider count. Those are not glamorous numbers, but they are the numbers that decide whether your AI feature feels like software or like a progress bar with a subscription.
The Hy3 lesson: anomalies are product signals
Tencent’s Hy3 remaining sticky at #8 with 10,660,809 requests is another reminder not to confuse community discourse with production usage. Hy3 has drawn practitioner scrutiny precisely because its OpenRouter usage looked high relative to its public mindshare. Max Woolf’s recent analysis of Hy3 and OpenRouter economics made the broader point well: intermediary usage data is rare because labs usually keep this telemetry private, and request volume can reveal what benchmarks and launch posts do not.
The Hacker News discussion around that analysis — 85 points and 71 comments at retrieval — centered on the right questions: price, routing, caching, defaults, and whether usage spikes reflect genuine developer choice or invisible distribution. That skepticism is healthy. But skepticism should not become dismissal. When a model is serving millions of weekly requests, the useful engineering response is not “I have not heard of it, so it does not count.” It is “what workload shape is making this model attractive?”
There are at least three practical readings here. First, request volume is downstream of integration. A model bundled into a popular app, router preset, SDK default, or cost-optimized workflow can outrank a technically superior model that developers reserve for expensive calls. Second, input-token economics matter more in agent systems than most pricing tables admit. If your workflow repeatedly sends long context, tool traces, retrieval snippets, or conversation state, cache behavior and input pricing can dominate the bill. Third, cheaper models can become more expensive than frontier models if they fail in ways that trigger retries, human review, or cascading tool calls. The invoice does not care that the model had a lower sticker price.
That is the core practitioner takeaway: benchmark on your own traffic shape. Do not run a cute prompt suite and call it done. Measure task success, latency distribution, total tokens including retries, cache hit rate, tool-call validity, refusal/error modes, and human escalation. If you are comparing a frontier model against a fast discount model, compare full workflow cost, not single-call cost. The cheap model that needs three tries and produces malformed JSON twice is not cheap; it is just billing you in operational entropy.
For teams choosing models this week, Arena should be used as a shortlist generator, not a deploy button. It helps identify the quality frontier and avoid obviously weak candidates. OpenRouter should be used as a market telemetry surface: it tells you where volume is flowing and which models may have compelling operational economics. Neither leaderboard knows your workload, your latency budget, your support burden, your compliance needs, or your tolerance for weird edge-case failures.
The split between the two rankings is the story. Arena says frontier quality is stable: Anthropic is still very strong, Google and OpenAI are close enough to deserve testing, and the top cohort is tight. OpenRouter says production gravity is pulling toward fast, cheap, broadly integrated models, with newcomers like Ling-2.6-flash and sticky outliers like Hy3 forcing practitioners to look beyond brand familiarity.
My read: the LLM market is entering its “database selection” phase. Everyone used to ask for the best database; grown-up teams learned to ask whether they needed Postgres, Redis, ClickHouse, S3, SQLite, or all of the above. LLMs are heading the same direction. The winning stack will not be one model worshipped at the top of a leaderboard. It will be a routing policy: premium reasoning where correctness pays for itself, cheap fast inference where throughput matters, and enough evaluation plumbing to know when the router is lying to you.
That is less satisfying than a clean ranking. It is also how real systems get shipped.
Sources: Arena AI Text Leaderboard, OpenRouter AI Model Rankings, Max Woolf on Hy3 and OpenRouter economics, Hacker News discussion