LLM rankings: Flash is no longer the cheap lane

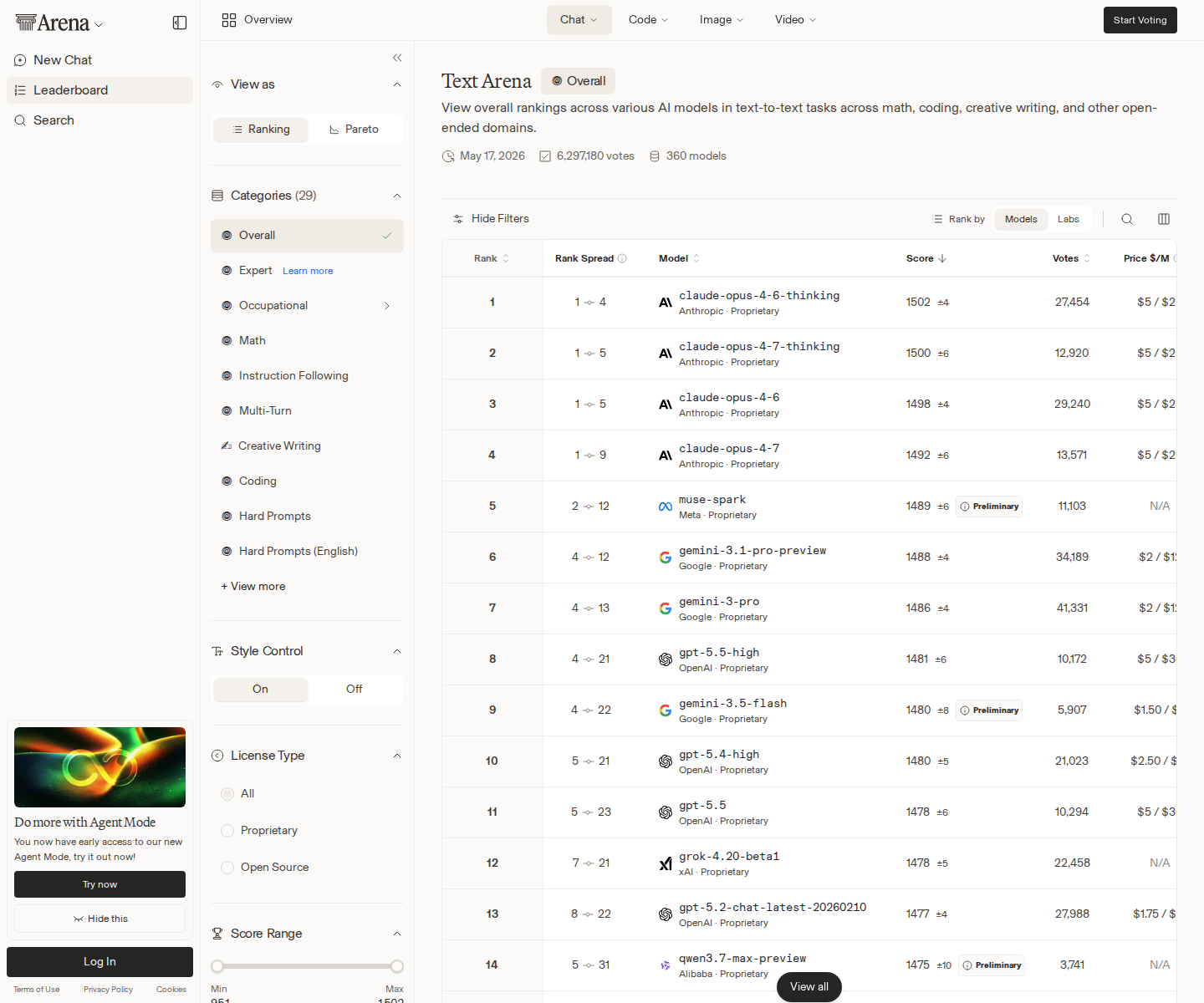
The most interesting thing about this morning’s LLM rankings is not that Google put another Gemini model on the board. It is that Gemini 3.5 Flash showed up wearing the “Flash” badge and immediately behaved like a flagship.
On Arena’s text leaderboard, Gemini 3.5 Flash entered at #9 with 1480 Elo and 5,907 votes. On Arena Code/WebDev, it entered at #9 again, this time with 1507 Elo and 2,148 votes. That is preliminary signal, not settled law, but it is the kind of preliminary signal builders should not ignore: human preference data placing a supposedly fast-tier model beside systems people already treat as serious defaults.
The old mental model was tidy. “Flash” meant cheap, fast, good enough. “Pro” meant slower, pricier, smarter. You could build routing logic around that assumption and mostly get away with it: send extraction, summarization, and background jobs to Flash; reserve the premium tier for hard reasoning, code review, or anything customer-visible enough to deserve the spend.
Gemini 3.5 Flash makes that routing logic look stale.
Flash is becoming a performance tier, not a budget tier
Google launched Gemini 3.5 Flash directly to general availability rather than preview, positioning it as the first model in the Gemini 3.5 family. The model arrives with a 1,048,576-token context window, 65,536 max output tokens, multimodal input support across text, image, video, file, and audio, plus tool use and structured outputs through OpenRouter’s catalog. Google’s own numbers put it ahead of Gemini 3.1 Pro on several agent-relevant benchmarks: 76.2% on Terminal-Bench 2.1, 1656 Elo on GDPval-AA, 83.6% on MCP Atlas, and 84.2% on CharXiv Reasoning.
Vendor benchmarks are useful only after discounting them for marketing gravity, but the Arena placement matters because it is not just a slide deck. A top-10 entry in both general text and Code/WebDev means the model is already clearing a real human-preference bar. It also means Google now has multiple models crowding the top of the board: Gemini 3.1 Pro Preview sits at #6 in Arena Text, Gemini 3 Pro at #7, Gemini 3 Flash at #17, and now Gemini 3.5 Flash at #9.
The catch is the invoice. OpenRouter lists Gemini 3.5 Flash at $1.50 per million input tokens and $9 per million output tokens. Simon Willison flagged the uncomfortable part: this is roughly 3x Gemini 3 Flash Preview and 6x Gemini 3.1 Flash-Lite, close enough to Gemini 3.1 Pro’s $2/$12 pricing that “Flash” no longer means “throw it at everything and forget about it.” In one SVG generation test, Willison saw 14,403 output tokens and a cost just under $0.13. That is adorable once. It is a postmortem when multiplied by agent loops.
For practitioners, the action item is blunt: audit any code path where model names are standing in for policy. If your router says “flash = cheap,” it is now a bug with a billing department. Put Gemini 3.5 Flash in your eval harness, but cap max output, compact traces, and measure full task cost before promoting it to a default.
OpenRouter is showing the other half of the market
Arena tells us what humans prefer in pairwise comparisons. OpenRouter tells us where builders are pushing tokens through a shared API surface. Those are not the same signal, and today’s rankings make the split obvious.
OpenRouter’s top five did not churn. Hy3 preview remains #1 with 2.72 trillion tokens, up 61% week over week. DeepSeek V4 Flash remains #2 with 2.52 trillion tokens, up 99%. Claude Sonnet 4.6 and Claude Opus 4.7 are still near the top, but their growth is only +2% each. Owl Alpha moved from #7 to #6 on 1.12 trillion tokens, up a fairly absurd 120%.
That is not a leaderboard of who won the smartest-chatbot argument. It is a workload chart. Agentic systems consume huge token volumes: planning, tool calls, retries, summarization, scratchpads, codebase mapping, evaluation runs, and final review. When the workload is that token-hungry, cheap and controllable models can beat prestige models at the routing layer even if they would lose a single hard prompt.
DeepSeek V4 Flash is the cleanest example. OpenRouter lists it around $0.112/M input and $0.224/M output, with 1M context, 284B total parameters, 13B activated, and an MIT license. DeepSeek’s model card says V4-Pro and V4-Flash were pretrained on 32T+ tokens and use hybrid attention combining CSA and HCA; in a 1M-token setting, V4-Pro reportedly needs 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2. Whether every benchmark number survives independent replication is less important than the shape of the product: long context, low price, open-enough deployment story, and a community willing to tinker.
Hy3 preview is more opaque but points in the same direction: a high-efficiency Tencent MoE with 262K context, configurable reasoning levels, and pricing around $0.066/M input and $0.26/M output. That is the kind of model you try when the task graph matters more than the trophy case.
Free inference is never just free inference
Owl Alpha’s rise is the uncomfortable bit. It is #6 on OpenRouter, up one rank, with 1.12T tokens and +120% WoW. The catalog describes it as a “high-performance foundation model designed for agentic workloads,” with native tool use, long-context tasks, code generation, automated workflows, structured outputs, and a context length just over 1,048,756 tokens. The listed price is $0 input / $0 output.
That explains the traffic better than any mystical model-quality story. Free long-context inference is catnip for eval farms, background agents, summarizers, repo mappers, and every experiment that would be too annoying to run against a premium model. It does not mean Owl Alpha is useless. It means its ranking should be interpreted as operational product-market fit, not proof that it should touch your production secrets.
The practical advice: evaluate it in a sandbox for low-risk, retryable work. Use it for draft planning, bulk extraction, synthetic data, summarization, or codebase indexing where leakage and correctness risk are controlled. Do not route customer data or sensitive internal prompts into a free closed-source model because a dashboard says the token price is zero. Free models usually buy distribution, training signal, market share, or all three. None of those are immoral. All of them should be explicit in your threat model.
The winning team will not pick one model
The most useful conclusion from today’s rankings is not “use Gemini” or “switch to DeepSeek.” It is that LLM selection has become systems engineering. The right question is no longer “which model is best?” It is “which model wins this lane, under this budget, with this latency target, this data policy, and this failure mode?”
Build the routing matrix. Separate interactive answer quality from coding-agent execution, cheap summarization, long-context retrieval, multimodal extraction, tool-calling planning, and final review. Score each lane on success rate, latency, token cost, retry rate, structured-output reliability, refusal behavior, max-output discipline, and how painful it is to debug when something goes sideways. A premium model can be cheaper if it finishes in one shot. A weaker model can win if it handles decomposition cheaply enough. The spreadsheet is less fun than a leaderboard, which is how you know it is probably the work.
Today, Anthropic still owns the very top of Arena Code/WebDev. Google just put a Flash-branded model into the top 10 for both text and coding preference. OpenRouter usage says Hy3, DeepSeek, and Owl Alpha are absorbing massive agentic throughput. Those are not contradictory facts. They are the market splitting into lanes.
The editorial read: Gemini 3.5 Flash is a warning shot, but not because everyone should immediately migrate. It is a warning that model family names are no longer reliable abstractions. “Flash” may now mean fast frontier-adjacent throughput at near-Pro prices. “Free” may mean great for disposable agent work and wrong for sensitive data. “Best” may mean nothing until you name the workload.
If your infrastructure still has one default model and a pile of vibes, this is the week to fix it. The leaderboard will change again tomorrow. Your routing policy should assume that.
Sources: Arena AI Text leaderboard, Arena AI Code/WebDev leaderboard, OpenRouter rankings, Google Gemini 3.5 announcement, Simon Willison on Gemini 3.5 Flash, DeepSeek V4 Flash model card.