MiniMax M3 Makes the Open-Weight Coding-Agent Cost Story Real

MiniMax M3 is not interesting because it has a million-token context window. Plenty of model launches have discovered that large context numbers make excellent slideware. M3 is interesting because MiniMax is trying to connect that context window to the part of AI tooling that actually burns money: long-running coding agents that read whole repositories, call tools thousands of times, retry after failed benchmarks, and then ask finance why the token bill looks like a small cloud migration.
The release is a direct shot at the current frontier-agent stack. MiniMax says M3 combines three capabilities that have mostly lived behind closed APIs: frontier-ish coding and agentic performance, up to a 1M-token context window, and native multimodal input for images and video. The company is also positioning it as open-weight, with weights and a technical report promised after launch. That last part matters, but it should be treated as pending until developers can inspect the license, serving requirements, tensor formats, and actual inference behavior outside MiniMax’s own stack.
The benchmark claims are big. MiniMax reports M3 at 59.0% on SWE-Bench Pro, 66.0% on Terminal-Bench 2.1, 34.8% on SWE-fficiency, 28.8% on KernelBench Hard, and 74.2% on MCP Atlas. Its model page also claims an 83.5 score on BrowseComp, above Opus 4.7’s listed 79.3, and a PostTrainBench score of 37.1, behind Opus 4.7 at 42.4 and GPT-5.5 at 39.3. Those numbers are enough to put M3 in the conversation. They are not enough to end it.
The cost story is the product story
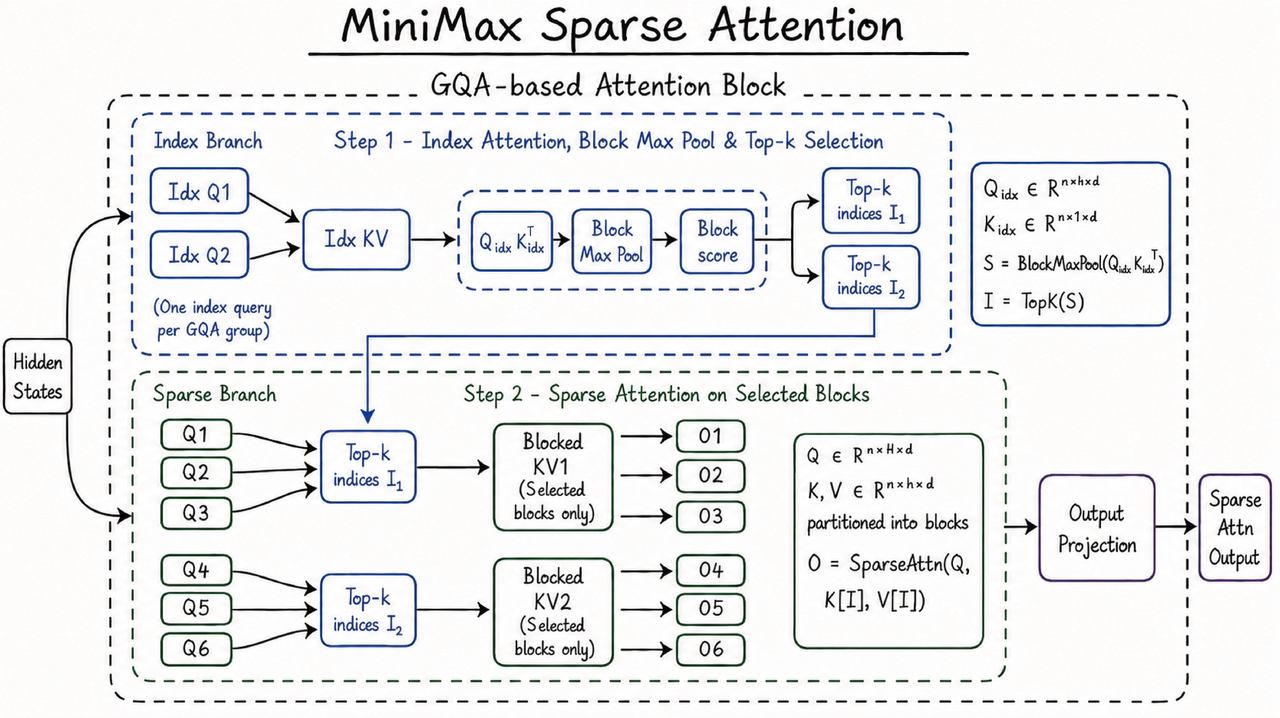
The architecture claim behind M3 is MiniMax Sparse Attention, or MSA. MiniMax describes it as a sparse attention design that selects KV blocks more precisely than earlier approaches and uses a “KV outer gather Q” operator path so each selected block is read once with contiguous memory access. Under M3’s head configuration, the company says this is more than 4× faster than open-source Flash-Sparse-Attention and flash-moba, while at 1M tokens M3’s per-token compute is 1/20 of the previous generation, with more than 9× faster prefill and more than 15× faster decoding.
If independent serving stacks reproduce even a meaningful fraction of that, this is more important than the leaderboard table. Coding agents are token furnaces. They ingest source trees, logs, design docs, test failures, tool outputs, shell transcripts, and often too much conversational history because nobody wants to build memory pruning correctly. A model that is slightly less capable than the top closed model but dramatically cheaper to keep alive over a 12-hour repo task can be the better default route.
MiniMax is clearly selling that angle. Its token plans are aggressive: Plus at $20 per month for roughly 1.7B M3 tokens, Max at $50 for 5.1B, and Ultra at $120 for 9.8B, with text, image, speech, and music sharing the same pool. The API supports up to 1M tokens, with a guaranteed minimum of 512K tokens according to the model page; calls at or below 512K input tokens use standard pricing, while longer calls use a higher long-context rate. Thinking mode can be toggled on or off at request time with the same pricing.
That is the right product shape for 2026 agent workloads. The winning model router is not going to send every task to the most expensive reasoning model by default. It will route broad repo understanding, context digestion, multimodal inspection, and cheap iterative repair loops to a workhorse model, then escalate the ambiguous architecture call or risky final patch to the strongest available frontier model. M3’s real test is not “does it beat Opus on a chart?” It is “does it make that routing strategy boring enough to use every day?”
Agent benchmarks still need a red pen
MiniMax deserves credit for publishing detailed evaluation methodology, because the details also show why agent leaderboards are slippery. Several coding evaluations used internal infrastructure and scaffolds such as Claude Code, Terminus 2, Mini-SWE-Agent, or Codex depending on the benchmark and comparison model. Terminal-Bench 2.1 was run with an 8C16G sandbox, a two-hour timeout, and max output tokens set to 128K. SWE Atlas-Codebase QNA used a 4C8G sandbox and a three-hour timeout. NL2Repo used restrictions meant to prevent cheating via external information and monitored shell commands.
That does not invalidate the scores. It makes them more useful, because it reminds practitioners that an “agent benchmark” is never just the model. It is the model plus scaffold, tool permissions, timeout policy, sandbox shape, prompt, verifier loop, retry behavior, and command interception. Change those and the ranking can move. A team evaluating M3 should reproduce its own workflow: same repo sizes, same build systems, same CI failures, same approval gates, same spend limits. Importing a vendor score without importing the operating conditions is how teams buy a leaderboard and ship a surprise.
The most compelling example in the release is not the SWE-Bench row. It is the CUDA kernel optimization task. MiniMax says M3 spent about 24 hours optimizing Hopper FP8 GEMM from a non-runnable Triton skeleton, making 147 benchmark submissions and 1,959 tool calls. Utilization reportedly rose from 7.6% to 71.3%, a 9.4× speedup. More interesting: MiniMax says most other models stopped making new progress within the first 30 submissions, while M3’s best solution arrived on submission 145.
That is the shape of real agent work. The hard part is not making one plausible first attempt. The hard part is staying oriented through plateaus, reading dense benchmark feedback, changing strategy without thrashing, and not torching the repo or the budget while doing it. If M3 is genuinely good at that kind of persistence, the surrounding infrastructure becomes mandatory: trace logs, checkpointed artifacts, resumable sessions, command allowlists, spend caps, approval records, and kill switches. Long context is not a governance layer. Tool competence makes governance more urgent, not less.
Open-weight is a promise until the weights land
MiniMax calls M3 the first open-weight model to bring frontier coding, million-token context, and native multimodality together. That may prove fair, but builders should keep the deployment checklist open. Sparse attention architectures can be excellent in a vendor-controlled environment and awkward elsewhere if the inference stack cannot exploit the operator path. The difference between “supports 1M context” and “can serve 1M context economically on my cluster” is where many long-context dreams go to quietly invoice themselves.
The practical questions are straightforward. What is the license? What hardware profile is realistic? Which inference engines will support MSA efficiently? Does prefix caching work cleanly? Can teams fine-tune without losing the sparse-attention advantages? What happens to latency and memory under multi-tenant agent workloads? Can the model’s multimodal and computer-use abilities be fenced with enterprise-grade permissions? Until those answers are public and reproducible, M3 is a strong API release with an open-weight trajectory, not yet a drop-in local replacement for closed coding agents.
Community reaction appears to be exactly where it should be: interested, skeptical, and waiting for weights. LocalLLaMA discussion surfaced around the launch focused on the right questions: sparse attention trade-offs, cost scaling versus full attention, licensing, and whether vendor benchmarks survive contact with independent harnesses. That is healthier than instant applause. The open-model world has learned, occasionally the expensive way, that release posts are not deployment plans.
For engineering teams, the near-term move is not to crown M3. It is to test it as a routing candidate. Give it broad codebase analysis, long-document digestion, multimodal bug reports, and iterative benchmark loops where cost matters. Compare not only task success but wall-clock time, tool-call count, token spend, retry behavior, and the number of human interventions required. If it gets close to the top closed models at a materially lower operating cost, that is a production-relevant result even if it loses a few trophy benchmarks.
MiniMax M3 looks like the first serious open-weight attempt to make long-horizon coding agents economically normal. That is the right ambition. The industry does not need another model that wins a chart and then becomes too expensive to use outside launch demos. It needs agent models whose cost curves, context behavior, and tooling surfaces can survive the boring parts of software engineering. M3 has made a credible claim. Now it has to survive independent runners, real repos, and the least forgiving benchmark of all: a team trying to ship on Friday without explaining a runaway agent bill on Monday.
Sources: MiniMax official blog, MiniMax M3 model page, VentureBeat technical context, OpenRouter model page