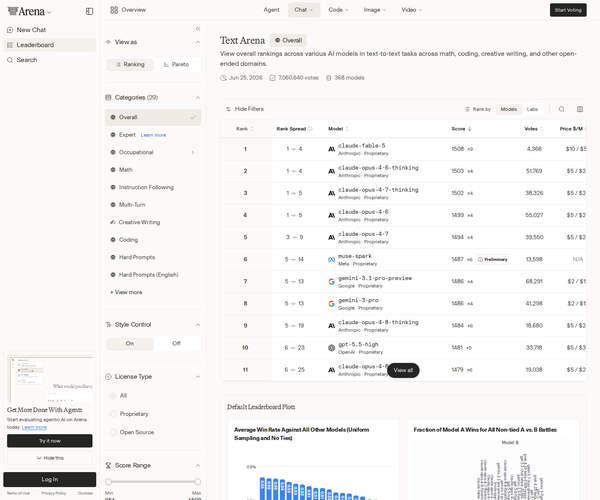
LlamaIndex v0.14.23 is a useful reminder that multimodal RAG is not “text RAG, plus images.” It is a plumbing problem. Documents, videos, screenshots, URLs, tool outputs, memory blocks, synthesis paths, and test harnesses all have to preserve structured media as structured media. The moment one layer forgets that