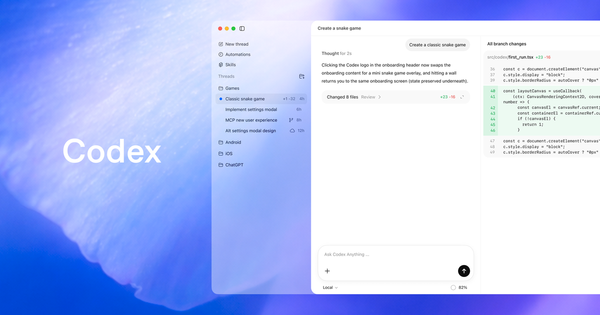
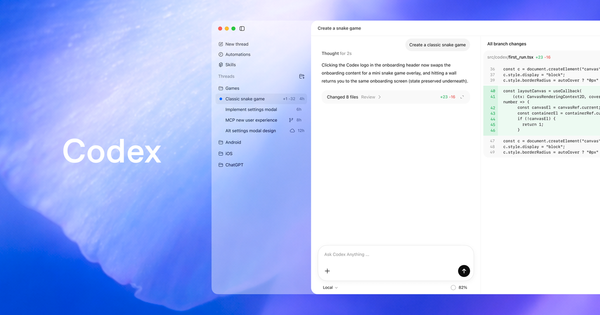
The first wave of enterprise AI infrastructure was easy to explain: buy GPUs, stand up models, argue about utilization. The next wave is messier. Agents do not just generate text; they call tools, move data, execute workflows, keep state, create audit problems, and occasionally do the wrong thing with machine