The Agent Framework Debate Is Really About Owning the Failure Modes

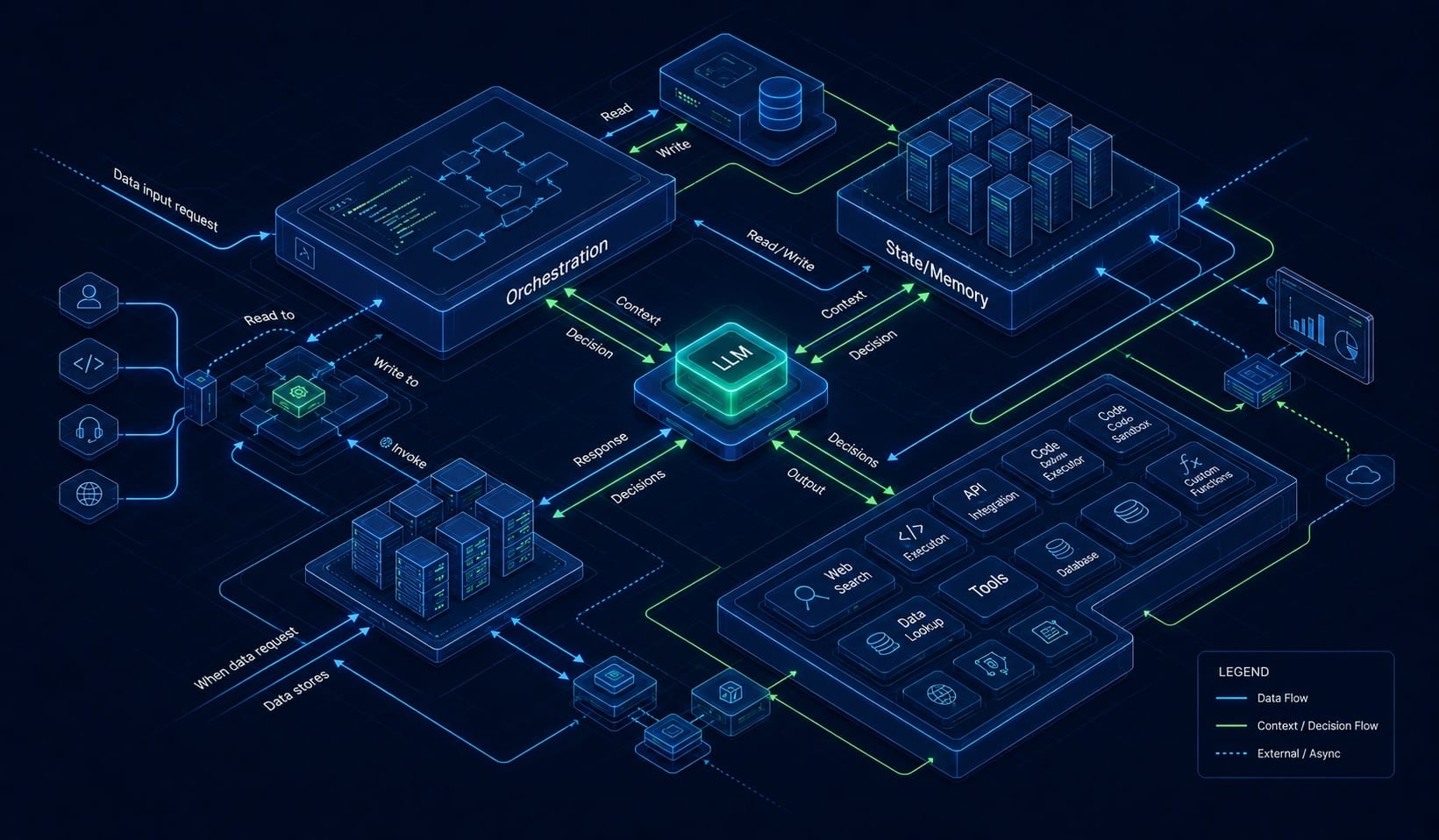
Most agent failures are not caused by models suddenly forgetting how to think. They are caused by teams handing architectural responsibility to a probabilistic component and then acting surprised when the system has no stable owner for state, retries, tools, memory, or auditability.
Benjamin Nweke’s new Towards Data Science piece lands because it says the quiet part plainly: many production agents are built backwards. Teams start with the desired autonomous behavior — “the agent should triage tickets,” “the agent should update the CRM,” “the agent should review pull requests” — and then expect the LLM’s reasoning loop to glue together context retrieval, tool calls, error handling, state transitions, and evaluation. That works beautifully in a demo because demos are short, controlled, and forgiving. Production is none of those things.
The article’s useful decomposition is familiar to anyone who has had to debug a real agent system: a decision layer, orchestration layer, tools/execution layer, memory/state layer, and evaluation/observability layer. The mistake is treating those as implementation details hiding behind the word “agent.” They are the system. The model is one component inside it.
The model should not be your orchestrator of last resort
Nweke describes a team that spent two days chasing plausible but wrong outputs before realizing the model and individual tools were technically working. The failure was architectural: too much integration responsibility had been assigned to “reasoning.” That is the pattern practitioners should watch for. If the model is implicitly deciding not only what to do next, but also how to recover from tool failures, which memory is fresh, how to reconcile conflicting state, and when a write is safe, you do not have an agent architecture. You have a vibes-based transaction manager.
The better split is boring and durable: ordinary code owns state, routing, retries, queues, freshness, idempotency, and write semantics. The LLM decides what to do next given prepared context and constrained options. That distinction sounds pedantic until something breaks. When the wrong customer record is updated, “the model reasoned badly” is not an incident report. Which state did it read? Which tool contract allowed the write? Which retry duplicated the action? Which trace proves the sequence? Those answers live outside the model.
This is also why “framework versus no framework” is the wrong debate. LangChain, LangGraph, CrewAI, AutoGen, Mastra, VoltAgent, Google ADK, and hand-rolled Python are not morally different categories. They are different ways of assigning ownership over orchestration, state, tool boundaries, retries, memory, and traces. A framework is useful when it makes those responsibilities explicit, inspectable, and testable. It is dangerous when it hides the exact behavior you will need during the first production incident.
That matters because adoption is no longer theoretical. Datadog’s State of AI Engineering report says agent framework adoption nearly doubled year over year, from more than 9% of organizations in early 2025 to almost 18% by early 2026, while the number of services using agentic frameworks more than doubled. Datadog also found that more than 70% of organizations now use three or more models, and that 69% of all input tokens in customer traces were system prompts. Translation: scaffolded agents are spreading, multi-model behavior is normal, and framework boilerplate is becoming a real latency and cost surface.
Observability has to answer whether the action was correct
The sharpest line in the TDS piece is: “logging tells you what happened. Observability tells you whether what happened was correct.” That distinction is not semantic garnish. Agent systems can execute successfully and still be wrong. A tool call can return 200, a workflow can complete, a trace can look clean, and the final answer can still violate policy, use stale data, duplicate work, or mutate the wrong entity.
Traditional application observability was already moving beyond logs into traces, metrics, and profiling. Agent observability has a harder job because the interesting failure is often semantic. Did the agent retrieve the right contract clause? Did it use the current inventory state or a cached one? Did the approval step happen before the write? Did two agents race through shared memory and each proceed confidently with a different version of reality? A green dashboard that cannot answer those questions is just a beautifully rendered shrug.
Google’s Agent Executor announcement is the infrastructure-market version of the same argument. Google is not open-sourcing durable execution, event logs, snapshotting, secure isolation, single-writer session consistency, connection recovery, and trajectory branching because prompt chains needed nicer branding. It is doing that because long-running agents behave like distributed systems. They wait for approvals, survive disconnects, resume after failures, branch for evaluation, and share state across actors. Those are runtime problems, not prompt-engineering problems.
OpenAI’s prompt-injection guidance adds the security version. Tool-using agents need source/sink analysis and constrained action surfaces because attacks increasingly look like social engineering: convince the agent to move data from an untrusted source to a dangerous sink. You do not solve that with a more motivational system prompt. You solve it by narrowing tools, enforcing consent or blocking around risky transmissions, and making the action boundary auditable.
Draw the failure map before choosing the stack
For engineering teams, the practical move is to stop evaluating agent frameworks as demo accelerators and start evaluating them as failure-mode ownership models. Before picking a framework, draw the system. What does the model actually decide? What is deterministic code? Where does memory live? Who can write it? What is fresh enough? How are tool calls validated? Which side effects require approval? Can you replay a run and see context, model choice, tool calls, retries, writes, evaluator scores, cost, and final output?
If those boundaries are unclear, adding another abstraction will not help. It may make the failure cleaner to describe in a conference talk, but it will not make it easier to debug at 2 a.m.
The multi-agent case makes this even less optional. Shared state is where subtle failures breed: one agent updates a record, another reads stale state, both proceed with confidence, and now the trace contains two locally rational paths that globally contradict each other. If your runtime does not define write ownership, freshness, locking or conflict resolution, and state-version visibility, the LLM is being asked to paper over a distributed-systems problem it cannot even fully observe.
None of this means teams should rebuild every agent from scratch as a maturity ritual. Native orchestration can be cleaner, but plain Python can still produce a haunted house if nobody owns state semantics. Conversely, a graph runtime with checkpointing, typed state, and trace integration can be exactly the right call for workflows with approvals and resumability. The deciding question is not “framework or custom.” It is “does this design make the failure modes explicit enough that we can test, observe, and govern them?”
The industry is moving from prompt craft toward runtime discipline. That is good. Production agents do not fail because developers lacked imagination. They fail because imagination got shipped without state contracts, tool boundaries, evals, and receipts. Frameworks are not the enemy. Unowned architecture is.
Sources: Towards Data Science, Datadog State of AI Engineering, Google Cloud, OpenAI