NVIDIA’s Model Card Generator Makes AI Governance Look Like a Build Artifact

AI governance keeps failing in the least dramatic place possible: the repo. Not the policy memo, not the executive risk committee, not the glossy “responsible AI” page. The real failure mode is that a model ships with unclear training-data notes, stale evaluation claims, vague limitations, missing license context, and a model card assembled by archaeology three days before a customer asks for it.
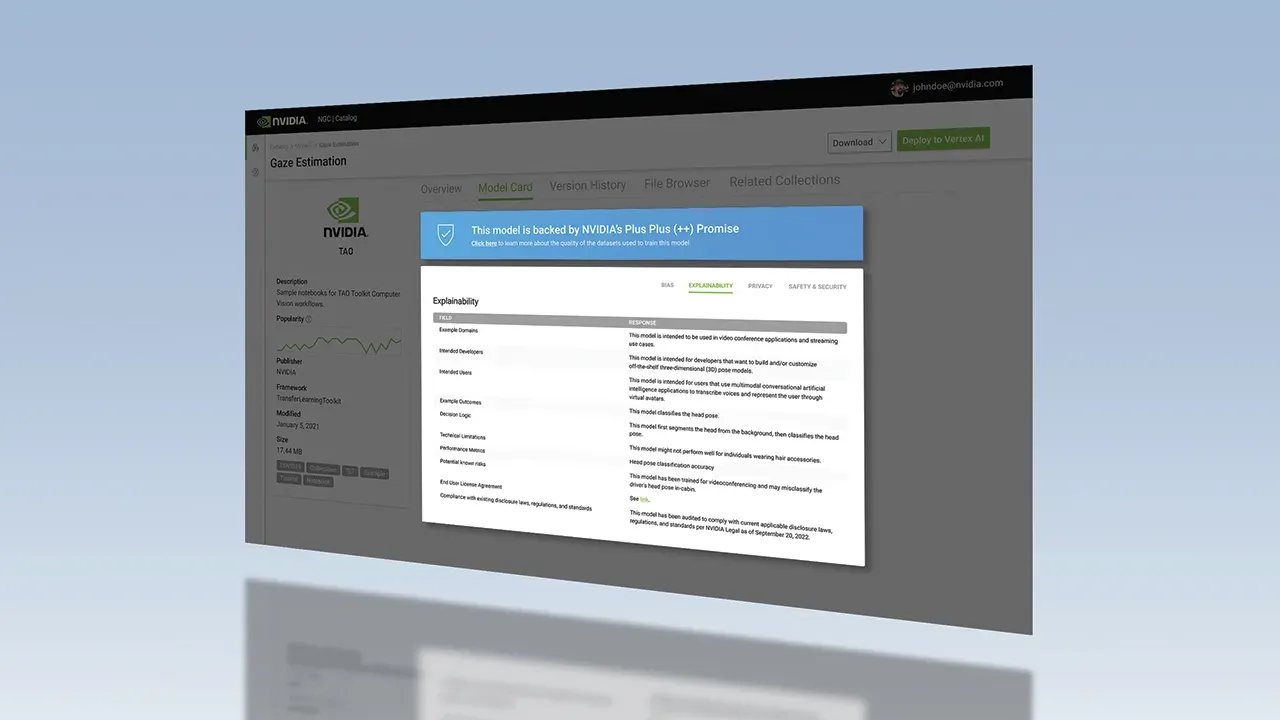
NVIDIA’s new Model Card Generator toolkit, or MCG, is interesting because it attacks that boring failure mode directly. The toolkit reads source material from GitHub, GitLab, Hugging Face, public web pages, ZIPs, PDFs, DOCX files, and Markdown; chunks and categorizes the content; runs retrieval and extraction through NVIDIA NIM and Nemotron RAG components; validates structured JSON; and renders a Model Card++ artifact with Bias, Explainability, Privacy, and Safety & Security subcards. In plain English: it tries to turn AI transparency documentation into a generated build artifact instead of a manual compliance scramble.
That is the right direction. Not because generated model cards remove accountability — they absolutely do not — but because repeatable, inspectable, versioned documentation is how software teams already manage things they cannot afford to improvise. If model documentation matters to regulators, customers, procurement teams, and downstream developers, then it should live near the release process, not in someone’s calendar reminder.
The useful feature is not the prose, it is the missing-field detector
NVIDIA frames MCG against rising documentation pressure from regimes including California AB-2013 and the EU AI Act. Model cards are supposed to describe intended use, license, training data, performance, limitations, and risks so that downstream users can understand what they are adopting. In practice, they often trail the model they describe. By the time a release is ready, the people closest to data curation, evaluation, safety testing, and deployment constraints may have moved on to the next checkpoint.
MCG’s pipeline is straightforward but important. Ingestion fetches and chunks repository content, separating documentation, config files, and code. Extraction uses a retrieval-augmented generation flow powered by NVIDIA Inference Microservices. Nemotron RAG embedding, specifically llama-nemotron-embed-1b-v2, and reranking, llama-nemotron-rerank-500m-v2, prioritize source passages. GPT-OSS-120B then applies NVIDIA’s Model Card++ template and field-level style guides to generate structured JSON, which is validated before rendering. A subcards stage produces Bias, Explainability, Privacy, and Safety & Security sections.
That sounds like a lot of machinery to write a Markdown file. It is not. The value is not that an LLM can write polished compliance prose. The value is that the system can turn repository evidence into structured claims and, just as importantly, surface “not found” or “information not available” when the evidence is missing. A governance generator that invents confident answers is worse than useless. A generator that exposes gaps is a release-review tool.
NVIDIA’s own results make that point better than any positioning line. In standardized testing, the toolkit generated a full model card in under a minute for most repositories. For the Model Card++ overview, NVIDIA reports Nemotron Nano 8B at 56 seconds with 97% completion and 92% accuracy; Cosmos Reason 2 at 86 seconds, 94% completion, and 82% accuracy; Parakeet at 65 seconds, 92% completion, and 87% accuracy; Proteina at 52 seconds, 94% completion, and 82% accuracy; and third-party models averaging about 80 seconds, 89% completion, and 80% accuracy. Across the broader full-card test set, NVIDIA cites 91% completion for the third-party baseline and 76% accuracy.
The more revealing test came when NVIDIA stripped all .pdf, .md, and .txt files from the same repositories and reran the toolkit against code alone. Average completion fell from 91% to 61%. Strict accuracy fell from 76% to 28%. That is not a bad result for MCG; it is a brutal review comment for the industry. Code and config can reveal architecture, dependencies, and some behavior. They cannot reliably reconstruct data provenance, evaluation scope, intended use, safety mitigations, deployment constraints, or why a model should not be used in a specific context.
Documentation debt is governance debt
Every engineering organization understands test debt and dependency debt. AI teams now need to treat documentation debt the same way. If the training data cannot be described from repository-linked evidence, that is not a paperwork gap; it is a provenance gap. If limitations are not recorded until a model is packaged, that is not a formatting problem; it is a release-risk problem. If safety and privacy claims live in Slack threads and slide decks, they are not auditable in any meaningful sense.
MCG’s architecture is valuable because it maps to the messy way enterprises actually operate. The toolkit is containerized, with separate orchestrator, ingestion, extraction, subcards, database, and task-queue services. It can run on-prem, in cloud, or on Kubernetes. It exposes both an interactive UI and a REST API. Models, templates, and field-level guides are configurable, so an organization can point to different NIM endpoints or compatible APIs, adapt Model Card++ to internal standards, or update disclosure requirements without rewriting the extraction pipeline. Outputs are rendered to Markdown and described as CycloneDX-compliant.
That configurability matters. AI governance requirements will not stay still. Procurement questionnaires change. Regulators refine expectations. Internal risk taxonomies mature. Customers demand different evidence in different industries. If the model-card process is a hard-coded form, it will rot. If it is a pipeline with templates and guides, it can evolve like the rest of the software supply chain.
NVIDIA also says Oracle is an early production infrastructure partner, deploying MCG pods and NIM pods on OCI Container Engine for Kubernetes inside a standard VCN architecture, backed by Object Storage for NIM models. Oracle’s setup uses Llama-3.3-Nemotron-Super-49B-v1 as the extraction model and Nemotron RAG for embedding and reranking. The partner detail is less interesting than the deployment shape: governance tooling is being placed next to enterprise AI infrastructure, not bolted on as a PDF generator after release.
How teams should actually use this
The wrong response is to treat MCG, or any model-card generator, as an accountability outsourcing machine. Generated documentation still needs review by people who understand the model, data, evaluation, license, safety posture, and deployment environment. An LLM can assemble and structure evidence; it cannot become the accountable owner of claims about bias, privacy, risk, or intended use.
The right response is to make model documentation part of CI. Require model repositories to include machine-readable metadata, dataset references, evaluation reports, license information, intended-use notes, out-of-scope-use warnings, risk mitigations, and deployment constraints. Run a generator to produce the draft artifact. Fail or warn when required fields are missing. Route gaps back to model owners before release. Review the final card like a code change, with diffs, approvers, and version history.
For platform teams, the most practical use may be as a documentation linter. If code-only extraction drops strict accuracy to 28%, that tells you what a reviewer would also discover the hard way: the repo is not self-describing enough. MCG can make that failure visible earlier. The model card itself is the artifact customers and auditors see; the missing-field report is the artifact engineers should care about before the customer ever asks.
There is also a supply-chain angle here. NVIDIA’s Trustworthy-AI GitHub repository had only modest public adoption at research time — 40 stars, 11 forks, and one open issue — but the pattern is bigger than that repo. AI artifacts increasingly need SBOM-like discipline: model lineage, data disclosures, risk cards, evaluation evidence, container metadata, endpoint behavior, and policy constraints. CycloneDX alignment hints at the same direction. The model is no longer just weights; it is an operational package that needs inspectable metadata around it.
The LGTM take: NVIDIA’s MCG toolkit is not glamorous, and that is why it is useful. AI governance will not be fixed by nicer principles pages. It will improve when transparency artifacts are generated, reviewed, versioned, and blocked on missing evidence the same way serious teams handle builds and tests. If your model card cannot be produced from repo-linked facts, the problem is not the generator. The problem is that your model is already shipping with undocumented assumptions.
Sources: NVIDIA Developer Blog, NVIDIA Trustworthy-AI GitHub, NVIDIA Trustworthy AI, CycloneDX