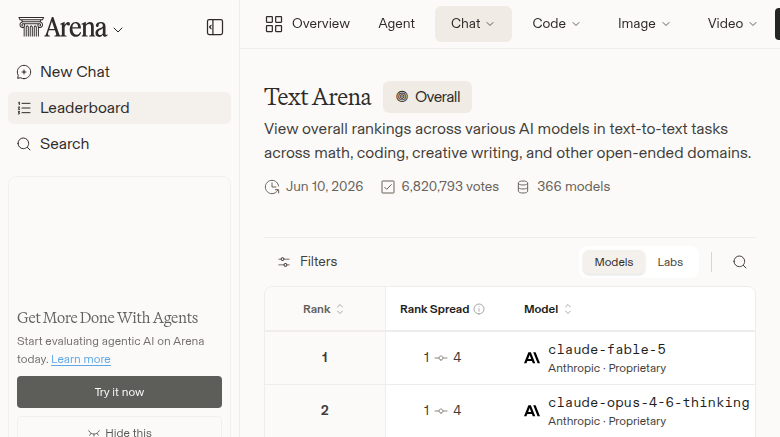
Coding agents are no longer a chatbot feature with a shell bolted on. They are a strange, expensive inference workload: long prompts, growing context, repeated turns, tool-call gaps, cache reuse, and enough concurrency to make tail latency matter more than the happy-path demo. That is why NVIDIA’s AgentPerf result