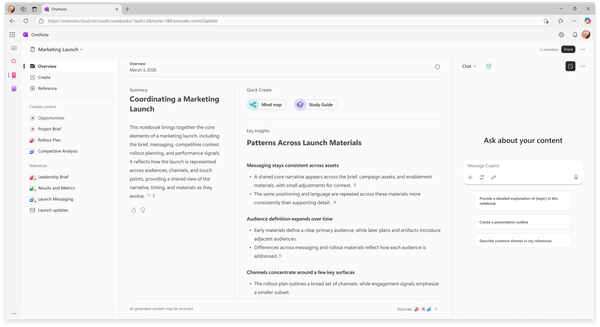
The most revealing agent-runtime bugs are rarely the ones with dramatic stack traces. They are the ones that feel like weather: a stream starts slowly, an async call stalls, the UI looks alive but stops moving, and nobody can quite prove whether the model, network, auth layer, callback stack, or