Synthetic Medical Images Are NVIDIA’s Most Practical Open Model Play This Week

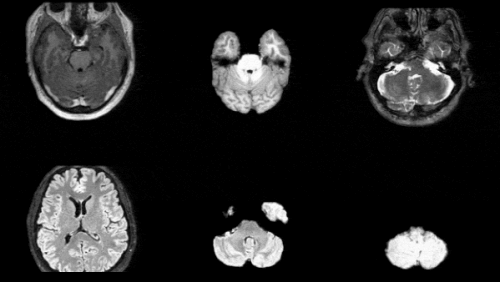
Synthetic medical data has spent years stuck between two unhelpful extremes: demos that look impressive in a slide deck, and clinical claims that arrive several validation steps too early. NVIDIA’s new NV-Generate-MR-Brain release is more interesting because it lives in the middle. It is not trying to convince anyone that generated MRI volumes are a substitute for hospital data. It is trying to make medical AI development less dependent on scarce, sensitive, inconsistently labeled 3D imaging data — and that is a much more useful pitch.
The release extends NVIDIA’s open-source NV-Generate-CTMR framework from CT into high-resolution brain MRI. The new model, listed as NV-Generate-MR-Brain or rflow-mr-brain, supports whole-brain and skull-stripped synthetic MRI volumes across T1w, T2w, FLAIR, and SWI contrasts. It also adds ControlNet support for specified anatomical structures and cross-sequence generation, which matters because real radiology workflows are not single-image toy problems. Teams need anatomy, modality, contrast, spacing, masks, and metadata to line up well enough that downstream models learn medicine rather than generator artifacts.
The useful part is the pipeline, not the pretty slices
NV-Generate-CTMR now spans four variants: ddpm-ct, rflow-ct, rflow-mr, and the new brain-focused rflow-mr-brain. The CT path supports volumes up to 512 x 512 x 768 and can produce paired image/mask data, including a 132-class segmentation vocabulary plus body-envelope labeling. The general MR path supports up to 512 x 512 x 128. The new brain model raises that to 512 x 512 x 256 for high-resolution neuro MRI.
Those dimensions are not trivia. In medical imaging, the difference between a 2D image generator and a controllable 3D volume generator is the difference between a useful research tool and a wallpaper engine. Segmentation models, registration pipelines, surgical planning tools, and radiology-assist systems care about spatial consistency. A plausible axial slice is not enough if the anatomy falls apart across adjacent slices or if the generated mask vocabulary does not match the model you are trying to train.
NVIDIA’s strongest engineering choice is packaging the release as infrastructure: code, weights, training configurations, inference scripts, papers, a browser demo, and explicit caveats around voxel spacing, field of view, contrast, and model variant. The project’s own warning that field-of-view selection is a major output-quality factor is exactly the sort of boring constraint that makes the work more credible. Synthetic data releases get dangerous when they hide the knobs and show only the gallery.
MAISI-v2 is about making iteration cheap enough to matter
The speed story is also practical. NVIDIA says MAISI-v1 used latent diffusion, while MAISI-v2 uses Latent Rectified Flow and delivers up to 33x acceleration over the earlier approach with improved image quality. The associated research describes moving from roughly 1,000 diffusion steps toward a much smaller number of inference steps — NVIDIA’s brief cites 30 — which is not just a benchmark detail. If a lab wants to generate cohorts repeatedly while varying anatomy, contrast, lesion placement, or masks, inference cost decides whether synthetic augmentation is a one-off experiment or part of the development loop.
The new MRI model is trained on MR-RATE, a large neuroimaging dataset with about 705,254 MRI volumes, 98,334 imaging studies, and 83,425 unique patients, paired with radiology reports and metadata. The published split lists 75,000 training patients, 3,425 validation patients, and 5,000 test patients. The Hugging Face card puts the primary repository at 8.1 TB, with co-registered data at 17.6 TB, atlas-registered data at 12.3 TB, and native-space NV-Segment-CTMR segmentations at 415 GB.
That scale matters, but the license matters just as much. MR-RATE is gated and released under CC-BY-NC-SA-4.0 for research and education, with commercial licensing through Forithmus. NVIDIA says most NV-Generate models use the NVIDIA Open Model License, while rflow-mr is research-only. This is not a generic image corpus where a startup can quietly train first and ask legal later. If you are building commercial medical AI, dataset provenance, patient privacy, de-identification policy, generated-data rights, and downstream model obligations need to be in the design review before the demo works.
Use synthetic data to stress systems, not to skip reality
The right first use case is not replacing private clinical data. It is controlled stress testing and augmentation. Generate rare tumor-mask configurations. Probe whether a segmenter fails when scanner protocol, contrast, or field of view changes. Bootstrap experiments before spending clinician annotation time. Build synthetic holdout sets that expose obvious brittleness. Then validate on real, institution-specific data before making any claim that touches clinical performance.
This is where many synthetic-data projects lose the plot. A generator can make downstream metrics go up for the wrong reasons. Models may learn synthetic texture, mask regularities, scanner shortcuts, or anatomy that is plausible but biased toward the generator’s training distribution. The more realistic the output looks to a human reviewer, the easier it is to overtrust it. Medical AI teams should assume generated data is both useful and suspect until an eval harness proves otherwise.
That harness should track downstream performance with and without synthetic augmentation, broken down by anatomy, pathology, contrast, scanner/protocol metadata, segmentation class, and institution. It should test whether synthetic artifacts are detectable by a classifier. It should keep real validation data sealed off from generation and tuning. It should record which generator version, prompt/control inputs, spacing, field of view, and mask vocabulary produced each training volume. If that sounds like too much bookkeeping, welcome to regulated software. The alternative is a model that performs beautifully on a synthetic benchmark and embarrassingly in deployment.
Philips MR business leader Ioannis Panagiotelis is quoted by NVIDIA saying that “synthetic, anatomically realistic neuro MR data from NV-Generate, combined with automated segmentation from NV-Segment and clinical reasoning capabilities from NV-Reason, help us design and validate AI solutions more efficiently.” That is the correct level of ambition: design and validation efficiency, not magic clinical replacement. The stack gets valuable when synthetic generation, segmentation, reasoning, and evaluation are connected into a repeatable workflow.
For practitioners, the action item is simple: treat NV-Generate-CTMR as a test fixture generator before treating it as a training-data factory. Pick one downstream task, define the failure modes you care about, generate controlled cohorts, and measure whether the synthetic data actually improves robustness on real validation sets. If the answer is yes, scale carefully. If the answer is no, the generator still taught you something about where your model is brittle.
NVIDIA’s medical AI release is valuable because it moves synthetic 3D imaging closer to reproducible infrastructure. The clinical value will not come from beautiful generated MRI slices. It will come from disciplined teams using those slices to ask harder questions before real patients are anywhere near the loop.
Sources: NVIDIA Developer Blog, NVIDIA-Medtech/NV-Generate-CTMR, MR-RATE on Hugging Face, MAISI paper, MAISI-v2 paper